由于我对二进制一窍不通, 这里以web_awd为主, 这也不是我的教程, 而是参考了其他大佬文章做的笔记这里主要参考了两位大佬nul1 和
简介 AWD: Attack With Defence, 强调攻防/实战/对抗, 综合考量队伍的渗透能力和防护能力
比赛中, 每个队伍维护多台服务器, 服务器中存在多个漏洞, 利用漏洞攻击其他队伍就可以进行得分, 修复漏洞避免其他队伍攻击可以防止丢分
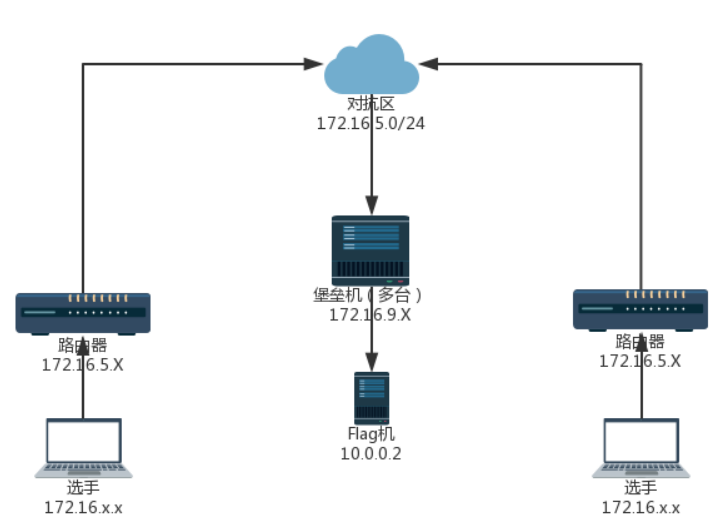
一般分配web服务器(多数为Linux) 某处存在flag(一般在根目录下) 肯能会提供一台流量分析虚拟机, 可以下载流量文件进行数据分析 flag在主办方的设定下每隔一定时间刷新一轮 各队一般有自己的初始分数 flag被其他队伍拿走, 该队就会扣除一定积分 扣除的积分由获取flag的队伍均分 主办方会对每个队伍的服务进行check, 服务器宕机扣除本轮flag分数, 扣除的分数由服务check正常的队伍均分 一般每个队伍会给一个低权限用户, 非root权限 网络情况
比赛中获取flag一般有两种模式
flag在根目录下, 读取flag内容提交即可得分 拿到其他队伍的shell后, 执行指定命令curl 10.0.0.2即可从上图flag机获取flag内容 比赛可能会告诉你其他队伍的IP, 也有可能不告诉你, 一般实在同一个C段或者B段, 可以利用nmap等攻击扫描发现其他队伍的IP
1 nmap -sn 192.168.71.0/24
或者用https://github.com/zer0h/httpscan 的脚本进行扫描
比赛套路 弱口令 修改弱口令密码, 主办方设置的密码极有可能时弱口令, 包括但不限于ssh/phpcms/wordpress, 需要立即修改口令, 改完自己队伍的之后可以看一下其他队伍的有没有修改.
不过, 有些比赛不允许修改后台口令, 如果修改视为服务器宕机
备份源码并查找预留后门 备份源码, 比赛开始第一件事就是备份源码, 将网站源码下载后复制一下, 用D盾扫描一份预留一份防止宕机, D盾扫描后也会发现一些预留后门, 第一时间删除后门后, 然后利用这个后门发起一波攻击
数据库备份 登录数据库备份, 当数据被删除的时候可以使用命令快速还原
1 mysqldump - u db_user - p db_passwd db_name > 1. sql / / 备份指定数据库
还原命令
1 mysql - u db_user - p db_passwd db_name < 1. sql / / 还原指定数据库
关闭不必要的端口 一些端口会存在漏洞, 为了保证安全, 我们关闭一些不必要的端口
部署WAF 这里推荐一个AoiAWD
CTFDefense
但是这里要注意规则是否允许第三方通防
也可以使用这个
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 <?php function customError ($errno , $errstr , $errfile , $errline echo "<b>Error number:</b> [$errno ],error on line $errline in $errfile <br />" ; die (); } set_error_handler ("customError" ,E_ERROR);$getfilter ="'|(and|or)\\b.+?(>|<|=|in|like)|\\/\\*.+?\\*\\/|<\\s*script\\b|\\bEXEC\\b|UNION.+?SELECT|UPDATE.+?SET|INSERT\\s+INTO.+?VALUES|(SELECT|DELETE).+?FROM|(CREATE|ALTER|DROP|TRUNCATE)\\s+(TABLE|DATABASE)" ;$postfilter ="\\b(and|or)\\b.{1,6}?(=|>|<|\\bin\\b|\\blike\\b)|\\/\\*.+?\\*\\/|<\\s*script\\b|\\bEXEC\\b|UNION.+?SELECT|UPDATE.+?SET|INSERT\\s+INTO.+?VALUES|(SELECT|DELETE).+?FROM|(CREATE|ALTER|DROP|TRUNCATE)\\s+(TABLE|DATABASE)" ;$cookiefilter ="\\b(and|or)\\b.{1,6}?(=|>|<|\\bin\\b|\\blike\\b)|\\/\\*.+?\\*\\/|<\\s*script\\b|\\bEXEC\\b|UNION.+?SELECT|UPDATE.+?SET|INSERT\\s+INTO.+?VALUES|(SELECT|DELETE).+?FROM|(CREATE|ALTER|DROP|TRUNCATE)\\s+(TABLE|DATABASE)" ;function StopAttack ($StrFiltKey ,$StrFiltValue ,$ArrFiltReq if (is_array ($StrFiltValue )){ $StrFiltValue =implode ($StrFiltValue ); } if (preg_match ("/" .$ArrFiltReq ."/is" ,$StrFiltValue )==1 ){ print "360websec notice:Illegal operation!" ; exit (); } } foreach ($_GET as $key =>$value ){ StopAttack ($key ,$value ,$getfilter ); } foreach ($_POST as $key =>$value ){ StopAttack ($key ,$value ,$postfilter ); } foreach ($_COOKIE as $key =>$value ){ StopAttack ($key ,$value ,$cookiefilter ); } if (file_exists ('update360.php' )) { echo "请重命名文件update360.php,防止黑客利用<br/>" ; die (); } function slog ($logs $toppath =$_SERVER ["DOCUMENT_ROOT" ]."/log.htm" ; $Ts =fopen ($toppath ,"a+" ); fputs ($Ts ,$logs ."\r\n" ); fclose ($Ts ); } ?>
使用方法:
将waf.php传到包含的文件目录 在页面中加入防护, 有两种做法, 根据情况二选一即可 在首页面加入代码
1 require_once ('waf.php' );
就可以做到页面防注入、跨站
1 2 3 4 5 6 PHPCMS V9 \phpcms\base.php PHPWIND8.7 \data\sql_config.php DEDECMS5.7 \data\common.inc.php DiscuzX2 \config\config_global.php Wordpress \wp-config.php Metinfo \include \head.php
在每个文件最前加上代码
1 2 Automatically add files before or after any PHP document. auto_prepend_file = 360 _safe3.php路径;
需要注意的是, 部署waf可能会导致服务不可用, 需要谨慎部署
文件监控
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 import osimport hashlibimport shutilimport ntpathimport timeCWD = os.getcwd() FILE_MD5_DICT = {} ORIGIN_FILE_LIST = [] Special_path_str = 'drops_JWI96TY7ZKNMQPDRUOSG0FLH41A3C5EXVB82' bakstring = 'bak_EAR1IBM0JT9HZ75WU4Y3Q8KLPCX26NDFOGVS' logstring = 'log_WMY4RVTLAJFB28960SC3KZX7EUP1IHOQN5GD' webshellstring = 'webshell_WMY4RVTLAJFB28960SC3KZX7EUP1IHOQN5GD' difffile = 'diff_UMTGPJO17F82K35Z0LEDA6QB9WH4IYRXVSCN' Special_string = 'drops_log' UNICODE_ENCODING = "utf-8" INVALID_UNICODE_CHAR_FORMAT = r"\?%02x" spec_base_path = os.path.realpath(os.path.join(CWD, Special_path_str)) Special_path = { 'bak' : os.path.realpath(os.path.join(spec_base_path, bakstring)), 'log' : os.path.realpath(os.path.join(spec_base_path, logstring)), 'webshell' : os.path.realpath(os.path.join(spec_base_path, webshellstring)), 'difffile' : os.path.realpath(os.path.join(spec_base_path, difffile)), } def isListLike (value ): return isinstance (value, (list , tuple , set )) def getUnicode (value, encoding=None , noneToNull=False ): if noneToNull and value is None : return NULL if isListLike(value): value = list (getUnicode(_, encoding, noneToNull) for _ in value) return value if isinstance (value, unicode): return value elif isinstance (value, basestring): while True : try : return unicode(value, encoding or UNICODE_ENCODING) except UnicodeDecodeError, ex: try : return unicode(value, UNICODE_ENCODING) except : value = value[:ex.start] + "" .join(INVALID_UNICODE_CHAR_FORMAT % ord (_) for _ in value[ex.start:ex.end]) + value[ex.end:] else : try : return unicode(value) except UnicodeDecodeError: return unicode(str (value), errors="ignore" ) def mkdir_p (path ): import errno try : os.makedirs(path) except OSError as exc: if exc.errno == errno.EEXIST and os.path.isdir(path): pass else : raise def getfilelist (cwd ): filelist = [] for root,subdirs, files in os.walk(cwd): for filepath in files: originalfile = os.path.join(root, filepath) if Special_path_str not in originalfile: filelist.append(originalfile) return filelist def calcMD5 (filepath ): try : with open (filepath,'rb' ) as f: md5obj = hashlib.md5() md5obj.update(f.read()) hash = md5obj.hexdigest() return hash except Exception, e: print u'[!] getmd5_error : ' + getUnicode(filepath) print getUnicode(e) try : ORIGIN_FILE_LIST.remove(filepath) FILE_MD5_DICT.pop(filepath, None ) except KeyError, e: pass def getfilemd5dict (filelist = [] ): filemd5dict = {} for ori_file in filelist: if Special_path_str not in ori_file: md5 = calcMD5(os.path.realpath(ori_file)) if md5: filemd5dict[ori_file] = md5 return filemd5dict def backup_file (filelist=[] ): for filepath in filelist: if Special_path_str not in filepath: shutil.copy2(filepath, Special_path['bak' ]) if __name__ == '__main__' : print u'---------start------------' for value in Special_path: mkdir_p(Special_path[value]) ORIGIN_FILE_LIST = getfilelist(CWD) FILE_MD5_DICT = getfilemd5dict(ORIGIN_FILE_LIST) backup_file(ORIGIN_FILE_LIST) print u'[*] pre work end!' while True : file_list = getfilelist(CWD) diff_file_list = list (set (file_list) ^ set (ORIGIN_FILE_LIST)) if len (diff_file_list) != 0 : for filepath in diff_file_list: try : f = open (filepath, 'r' ).read() except Exception, e: break if Special_string not in f: try : print u'[*] webshell find : ' + getUnicode(filepath) shutil.move(filepath, os.path.join(Special_path['webshell' ], ntpath.basename(filepath) + '.txt' )) except Exception as e: print u'[!] move webshell error, "%s" maybe is webshell.' %getUnicode(filepath) try : f = open (os.path.join(Special_path['log' ], 'log.txt' ), 'a' ) f.write('newfile: ' + getUnicode(filepath) + ' : ' + str (time.ctime()) + '\n' ) f.close() except Exception as e: print u'[-] log error : file move error: ' + getUnicode(e) md5_dict = getfilemd5dict(ORIGIN_FILE_LIST) for filekey in md5_dict: if md5_dict[filekey] != FILE_MD5_DICT[filekey]: try : f = open (filekey, 'r' ).read() except Exception, e: break if Special_string not in f: try : print u'[*] file had be change : ' + getUnicode(filekey) shutil.move(filekey, os.path.join(Special_path['difffile' ], ntpath.basename(filekey) + '.txt' )) shutil.move(os.path.join(Special_path['bak' ], ntpath.basename(filekey)), filekey) except Exception as e: print u'[!] move webshell error, "%s" maybe is webshell.' %getUnicode(filekey) try : f = open (os.path.join(Special_path['log' ], 'log.txt' ), 'a' ) f.write('diff_file: ' + getUnicode(filekey) + ' : ' + getUnicode(time.ctime()) + '\n' ) f.close() except Exception as e: print u'[-] log error : done_diff: ' + getUnicode(filekey) pass time.sleep(2 )
批量脚本 比赛中我们的对手不止有一个, 这里就需要我们批量getshell, 批量提交flag
就像上面所说的预留后门, 不需要专门去打, 可以直接批量getshell
可以使用discuz-ml-rce
flag也是批量提交效率才会高一些
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 import sysimport jsonimport urllibimport httplibserver_host = '10.10.0.2' server_port = 80 def submit (team_token, flag, host=server_host, port=server_port, timeout=5 ): if not team_token or not flag: raise Exception('team token or flag not found' ) conn = httplib.HTTPConnection(host, port, timeout=timeout) params = urllib.urlencode({ 'token' : team_token, 'flag' : flag, }) headers = { "Content-type" : "application/x-www-form-urlencoded" } conn.request('POST' , '/api/submit_flag' , params, headers) response = conn.getresponse() data = response.read() return json.loads(data) if __name__ == '__main__' : if len (sys.argv) < 3 : print 'usage: ./submitflag.py $team_token $flag' sys.exit() host = server_host if len (sys.argv) > 3 : host = sys.argv[3 ] print json.dumps(submit(sys.argv[1 ], sys.argv[2 ], host=host), indent=4 )
流量日志 通过流量、日志的分析:
1.感知可能正在发生的攻击,从而规避存在的安全风险
2.应急响应,还原攻击者的攻击路径,从而挽回已经造成的损失
3.学习别人的攻击方法
基于流量监控来实现,一个简单的脚本如下:
1 2 3 4 5 6 7 8 9 10 11 12 <?php date_default_timezone_set ('Asia/Shanghai' );$ip = $_SERVER ["REMOTE_ADDR" ]; $filename = $_SERVER ['PHP_SELF' ]; $parameter = $_SERVER ["QUERY_STRING" ]; $time = date ('Y-m-d H:i:s' ,time ()); $logadd = '来访时间:' .$time .'-->' .'访问链接:' .'http://' .$ip .$filename .'?' .$parameter ."\r\n" ;$fh = fopen ("log.txt" , "a" );fwrite ($fh , $logadd );fclose ($fh );?>
手工防御 1 find / -name *flag* #查找flag位置
1 find .|xargs grep "password" #查找password
1 netstat -antulp | grep EST #查看以建立的连接和进程
1 2 kill PID killall <进程名> #结束进程
1 netstat -ant|awk|grep |sed -e-e |sort|uniq -c|sort -rn #检测TCP连接数量
1 chattr +i /etc/resolv.conf #chattr命令防止系统中某个关键文件被修改